今天又看了一篇好玩的关于RAG玩法的论文,叫做 SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION 。 核心思想很有意思,让LLM自己对自己说的话反思反思(脑海里不由得就想起前不久某知名主播说的让我们反思的话了)。接下来我就大致介绍一下这个方法…
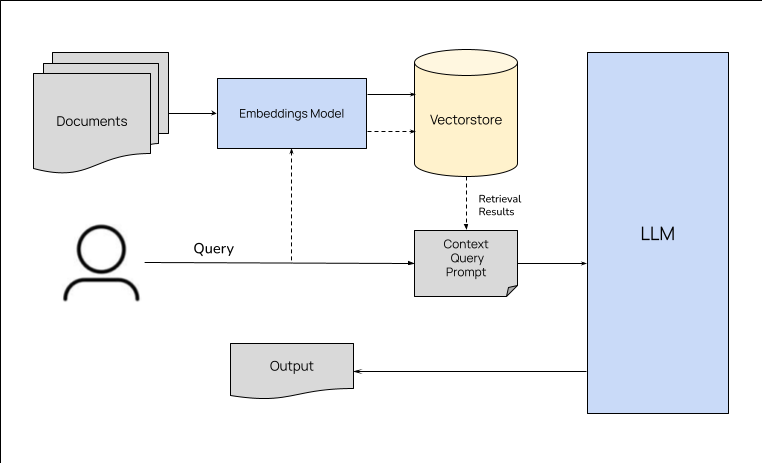
今天看了一篇来自于llmstack的创始人及CTO写的关于RAG的文章,正好最近在研究怎么玩本地知识库来着,感觉这篇文章很有帮助,这里翻译一下分享给大家,不过有时间的话更建议大家去看原文。 什么是检索增强生成? 如果你一直在向量存储或其他数据库中查找数据,并在生成输出时将相关信息作为上下文传递给 LLM,那么你已经在进行检索增强生成了。检索增强生成…
最近在研究如何将大语言模型结合本地知识库进行问答,虽然网上已经有很多教程,但大部分都是基于LangChain进行文本分割,然后调用模型向量化的API。这种方式的确很简单,但有这么几个前提: 大模型不使用ChatGPT的话,其实效果很差 尽管有多重切分方式,但还是很容易把文档中的一些语义撕裂。 由于众所周知的原因,使用ChatGPT的embeddin…
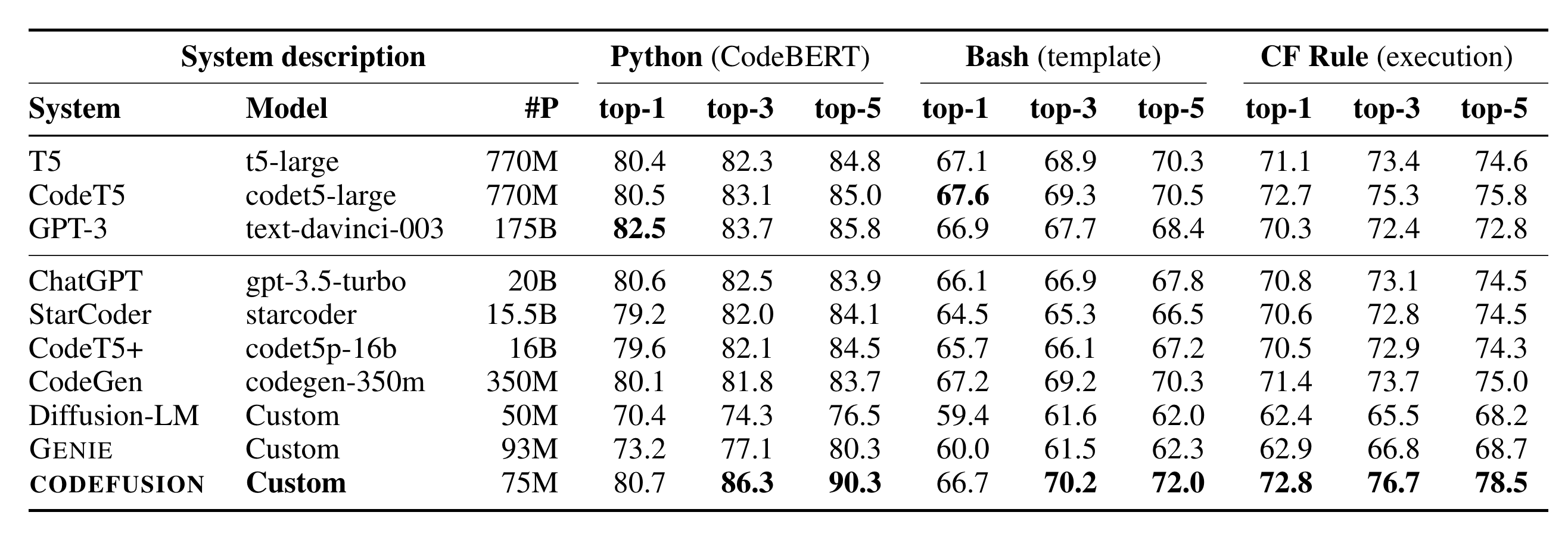
微软在10.26日发表了一篇论文CODEFUSION: A Pre-trained Diffusion Model for Code Generation,主要内容是提出了一个叫做CodeFusion的模型,它是一个基于扩散模型的从自然语言到代码生成模型,相对于论文提到的这个模型,更劲爆的是论文中的一张表格:看到图中的System descript…
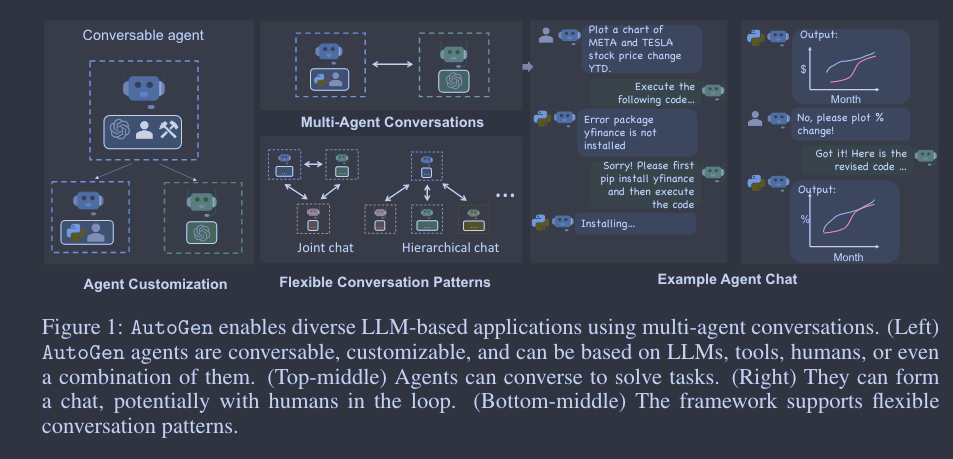
摘要 AutoGen 是一个开源框架,允许开发人员通过多个代理构建 LLM 应用程序,这些代理可以相互对话以完成任务。AutoGen 代理是可定制的、可对话的,并能以各种模式运行,这些模式采用 LLM、人类输入和工具的组合。使用 AutoGen,开发人员还可以灵活定义代理交互行为。自然语言和计算机代码都可用于为不同应用编程灵活的对话模式。AutoG…
前几天我分享了一篇跟Agent研究有关的文章,文章最后说过我还有一篇想要分享的,今天我就给大家带来了,它就是 “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation”。 我们知道,LLM不仅能够生成文本,还能进行复杂的任务和计算。然而,尽管这些模型具有巨大的…
好久没更新论文的分享了,今天来给大家分享一篇最近阅读的个人感觉非常有价值的一篇:MEMGPT: TOWARDS LLMS AS OPERATING SYSTEMS。我们都知道无论是ChatGPT、LLaMA、Claude等等大模型,虽然支持结合上下文进行对话,但这个对话长度实际是受限的,尤其是如果想进行长文档处理的时候就更头疼了,那么对于大模型这种…

如今国际上各种大语言模型蜂拥而至,但我们个人或者小公司想玩一个大模型要么花钱买硬件要么花钱买服务,因为大型语言模型(LLMs)虽然厉害,但部署起来非常困难!此外,这些巨型语言模型就像是那些吃不胖的人,吃了无数的数据,练了无数的参数,但是一到要“出门”工作的时候,问题来了。它们需要的计算资源和内存就像是一个永无止境的黑洞,让人望而却步。 今天我要讲的…

Abstract 我们呈现了一套能处理高达 32,768 个token的长上下文语言模型(LLMs)。这些模型是基于 LLAMA 2 通过持续预训练而得,利用了更长的训练序列,并在一个长文本被放大采样的数据集上进行训练。我们对这套模型进行了全面评估,包括语言建模、合成上下文探测任务和多种研究基准测试。在研究基准测试中,我们的模型在大部分常规任务上都…

LLaMA 2 刚发布没多久,Meta又推出了它的升级版,LLaMA 2 Long正式登场!性能上全面超越LLaMA 2。和其他竞争对手相比也丝毫不弱,甚至能超越ChatGPT(3.5)。 目前虽然市面上已经有很多大语言模型(LLMs),但我们都知道它们都存在一个问题,就是处理长上下文的时候容易出现健忘和胡说八道的情况。目前我个人若需要处理长文本的…