LLaMA 2 刚发布没多久,Meta又推出了它的升级版,LLaMA 2 Long正式登场!性能上全面超越LLaMA 2。和其他竞争对手相比也丝毫不弱,甚至能超越ChatGPT(3.5)。

目前虽然市面上已经有很多大语言模型(LLMs),但我们都知道它们都存在一个问题,就是处理长上下文的时候容易出现健忘和胡说八道的情况。目前我个人若需要处理长文本的时候要么切成一段段的分批总结处理,粗糙一点也可以使用Claude,但对于开源LLM来说,就算微调过也很难处理长文本内容。随着模型规模的增加和应用场景的多样化,如何有效地扩展这些模型以处理更长的上下文变得越来越重要。
这篇论文提供了一种全面的方法来解决这个问题,包括模型设计、评估和实用性等多个方面。特别是,它提出了一系列能够处理高达32,768个token的上下文窗口的模型,并进行了广泛的评估和比较。
这篇论文的研究主要关注以下几个方面:
- 有效的长上下文支持:论文提出了一系列模型,这些模型可以有效地处理高达32,768个token的上下文窗口。
- 性能评估:作者对这些模型进行了广泛的评估,包括语言建模、合成上下文探测任务以及多种研究基准测试。
- 指令调优:论文还介绍了一种成本有效的指令调优过程,这个过程不需要人工注释的长指令数据。
- 模型与其他解决方案的比较:这些模型在多个长上下文任务上超过了其他开源长上下文模型,如Focused Transformer、Yarn等。
- 有效的上下文利用:论文还探讨了如何更有效地利用长上下文,以提高模型在各种任务上的性能。
方法简介
在论文的第二章简单介绍了一下此次研究的方法:
- 持续预训练(Continual Pretraining):随着序列长度的增加,训练过程中的计算负担也会因为二次方的注意力计算而显著增加。本研究基于一个假设:通过从短上下文模型开始持续预训练,能够学习到类似的长上下文能力。为了实施持续预训练,作者几乎完全保留了原始的 LLAMA 2 架构,只是对位置编码做了必要的调整,以便模型能够处理更长的序列。
- 位置编码:通过一些初步的实验,作者发现了 LLAMA 2 位置编码(PE)的一个核心问题,它阻止了注意力模块有效地处理远距离的令牌信息。为了解决这个问题,我们对 RoPE 位置编码做了一些简单但必要的修改,主要是减小了旋转角度(由超参数“基频 b”控制),以减轻对远距离令牌的衰减效应。
- 数据组合:基于已修改的 PE 的模型,探讨了不同的预训练数据组合,以增强长上下文能力,包括调整 LLAMA 2 预训练数据的比例或加入新的长文本数据。最终发现,对于长上下文的持续预训练,数据质量通常比文本长度更为重要。
- 优化详情:保持每批次的令牌数量不变,增加序列长度,持续地预训练 LLAMA 2 的checkpoints。所有模型都在 100,000 步中总共训练了 400B 令牌。有了 FLASH ATTENTION,增加序列长度时的 GPU 内存开销几乎可以忽略,但在将 70B 模型的序列长度从 4,096 增加到 16,384 时,发现速度下降了约 17%。对于 7B/13B 模型,使用了 2e−5 的学习率,并配合了 2000 步的预热期的余弦学习率计划。而对于较大的 34B/70B 模型,作者发现降低学习率(1e−5)对于获得单调递减的验证损失非常重要。
- 指令调优(Instruction Tuning)
- 由于长上下文场景下收集人类示范和偏好标签是复杂和昂贵的,作者找到了一种简单且便宜的方法,它通过利用预先构建的大型多样化的短提示数据集,在长上下文基准上表现出意想不到的好效果。具体而言就是使用了 LLAMA 2 CHAT 中使用的 RLHF 数据集,并通过 LLAMA 2 CHAT 本身生成的合成自我指导长数据对其进行了扩展,希望模型能通过大量的 RLHF 数据学习到各种技能,并通过自我指导数据将这些知识应用于长上下文场景。
- 数据生成过程主要关注 QA 格式的任务:从预训练语料库中的长文档开始,随机选择一段内容,并提示 LLAMA 2 CHAT 根据文本内容编写问题-答案对。收集长答案和短答案并使用不同的提示。随后进行了一个自我评估步骤,提示 LLAMA 2 CHAT 验证模型生成的答案。对于生成的 QA 对使用原始长文档(截断以适应模型的最大上下文长度)作为上下文来构造训练实例。
- 对于短指令数据组合成 16,384 tokens的序列。对于长指令数据,在右侧添加填充tokens,以便模型能够单独处理每个长实例,而无需截断。尽管标准的指令调优仅计算输出令牌上的损失,但作者发现在长输入提示上也计算语言模型损失对于在下游任务上持续改进(第 4.3 节)是非常有益的。
模型表现
作者从3个方面给出了模型的表现结果,包括预训练评估,指令调优的结果以及人类评估的结果。
预训练评估
对于Short Tasks,总的来看,在多数情况下,模型的表现与 LLAMA 2相当,甚至更好。特别是,在编程、数学和知识密集的任务如 MMLU 上,模型的表现有了明显提升。此外,模型在 MMLU 和 GSM8k 上超过了 GPT-3.5,这与先前一项观察到短任务表现下降的研究形成鲜明对比。
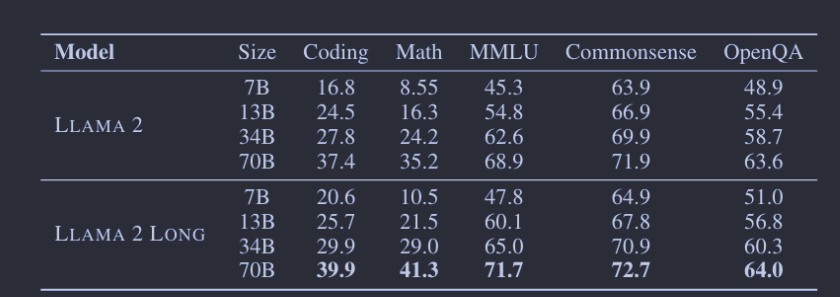
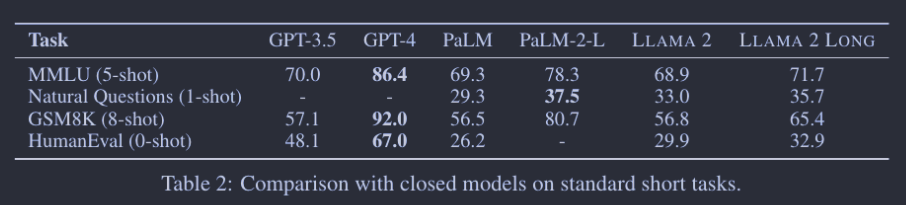
对于 Long Tasks, 与之前主要依靠困惑度和合成任务进行评估的研究不同,这项研究采用了实际的语言任务,如NarrativeQA、QuALITY、Qasper和QMSum进行了0-shot、1-shot和2-shot评估。评估重点放在了问答风格的任务上,因为这些任务更便于进行提示设计和自动评估。如果输入提示超过模型的最大输入长度(16,384个令牌),则会进行截断。研究还与其他几种开源的长上下文模型(如Focused Transformer、YaRN、Xgen、MPT和Together’s LLAMA 2fork)进行了比较。结果显示,他们的模型在多数情况下性能优于其他模型,特别是在7B规模上。唯一能与之匹敌的是一个经过大型监督数据集微调的模型“Together-7B-32k”。
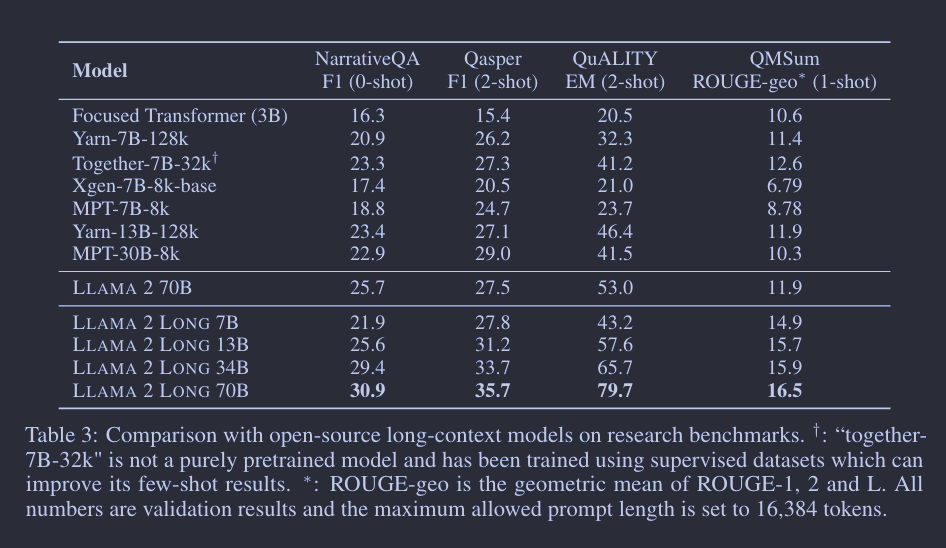
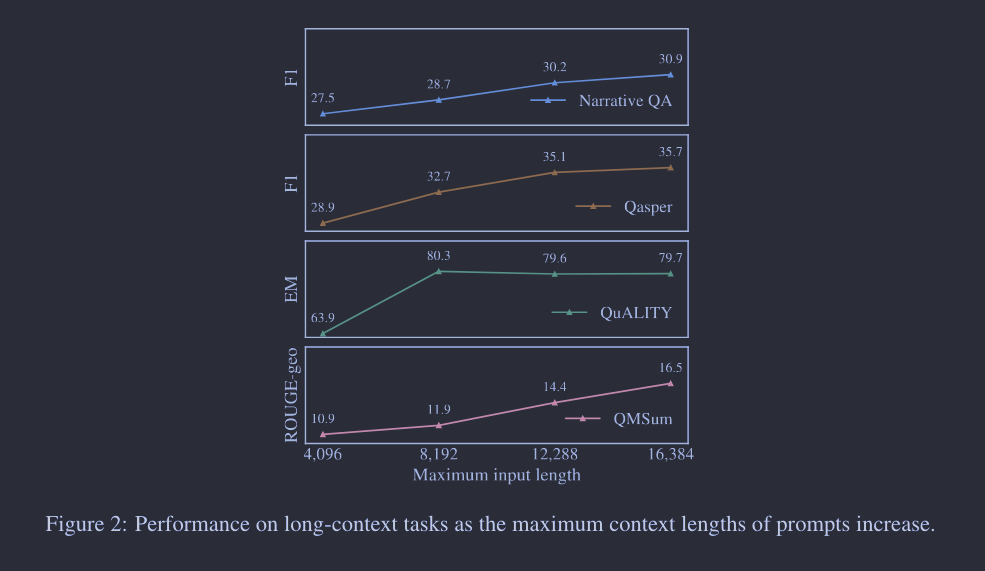
此外,如何证实它能有效利用扩大的上下文窗口?通过下图分析,研究发现随着上下文长度的增加,模型在各种长任务上的性能也逐渐提升。受到之前研究的启发,该模型在语言建模损失与上下文长度之间呈现出“幂律加常数”的关系。这意味着两个关键点:
- 尽管性能增益逐渐减小,但模型的性能(尤其是在语言建模损失方面)还是会继续提升,直到文本 token 数量达到32,768。研究以其70B规模的模型为例,说明如果上下文长度加倍,预期损失将以特定因子减少。
- 更大的模型(由曲线的较大β值表示)能更有效地利用上下文信息。
指令调优结果
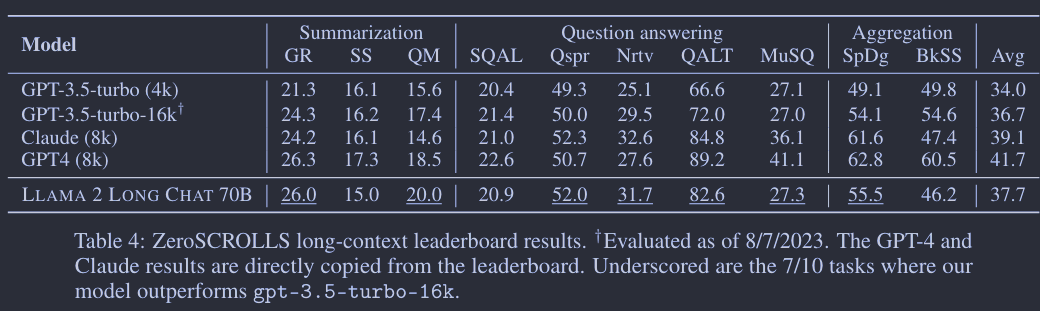
作者使用模型在ZeroSCROLLS和LEval两个长上下文数据集上进行了性能评估。ZeroSCROLLS包含10个涵盖摘要、问答和多文档聚合任务的长上下文数据集。作者使用了一个70B规模的模型,并且在7个任务中超过了gpt-3.5-turbo-16k,即便该模型没有使用任何人工标注的长上下文数据。在LEval数据集上,模型也展现了令人印象深刻的性能,特别是在问答任务上。
然而,评估长上下文语言模型(LLMs)有其困难和局限性。自动评估指标在多个方面都不完善,例如在摘要任务中通常只提供一个基准摘要,而n-gram匹配指标不一定能准确反映人类偏好。此外,在问答和聚合任务中,截断输入上下文可能导致丢失重要信息。还有一个问题是,许多私有模型没有公开他们的训练数据细节,这在进行公共基准测试时可能引发潜在的数据泄露问题。
人类评估
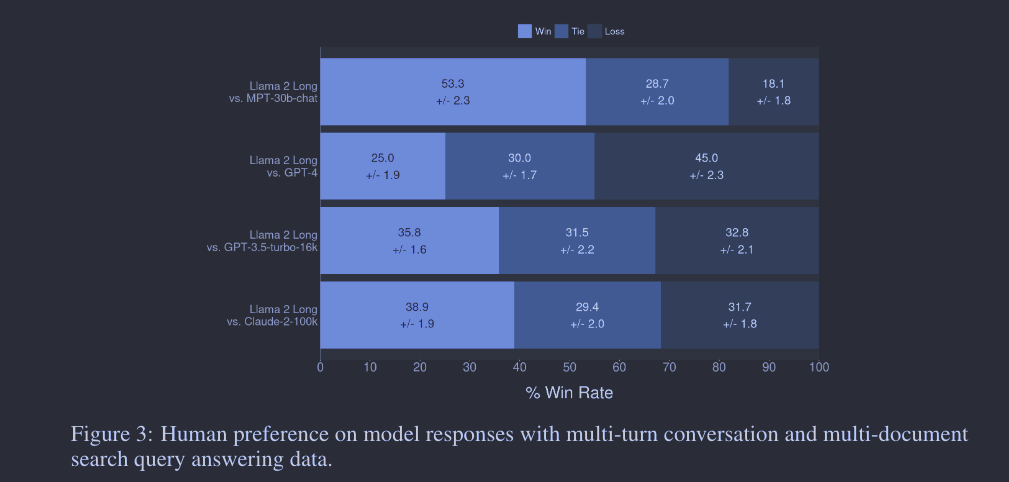
除自动评估外,研究者还进行了人工评估来衡量模型在多轮对话和多文档搜索查询回答等应用场景中的性能。人工评估是由3名不同的人类注释员进行的,涉及2,352个样例。这些评估更准确地反映了长上下文模型的回应质量,因为人类更擅长评价答案在帮助度、诚实度和安全性方面的多样性。结果显示,尽管只有少量的指令数据,研究中的模型在性能上仍能与其他高级模型如MPT-30B-chat、GPT-3.5-turbo-16k和Claude-2竞争。文中也强调,人工评估长上下文任务具有挑战性,通常需要经验丰富和技能熟练的注释员。研究者希望这项研究能推动长上下文自动评估方法的进一步发展,同时也展示了他们的模型在长上下文任务中的应用潜力。
方案分析
作者在第四章通过 ablation experiments 来验证设计选择并量化这些选择对最终性能的贡献。
- 位置编码(Positional Encoding):作者发现原有的 LLAMA 2 架构中使用的 ROPE 位置编码方法不适合处理超过 4,000-6,000 个令牌的长文本。因此,他们调整了 ROPE 的基频(从 10,000 提升到 500,000)以减小注意力衰减。他们还比较了其他编码方法,如 PI 和 XPOS,并发现调整基频的 ROPE(ROPE ABF)在所有情况下都表现最好。
- 预训练数据组合(Pretraining Data Mix):作者尝试了不同的数据组合策略,特别是提高长文本数据的比重。结果显示,调整数据长度分布并没有带来显著的好处,而数据本身的质量才是关键。
- 指令微调(Instruction Tuning):对预训练的模型进行了多种微调策略,并发现即使仅使用短指令数据进行微调,模型在长上下文任务上的表现也明显优于 LLAMA 2。
- 训练过程(Training Curriculum):作者探讨了是否从头开始用长序列进行预训练会比持续预训练更有效。结果表明,通过从短上下文模型开始的持续预训练,可以在几乎不损失性能的情况下节省约 40% 的计算资源。
这一章我理解是这篇论文最核心的一节了,结合论文最后的附录部分可以深入研究论文提出的算法策略以及带来的价值。
安全问题
虽然在不同下游任务上表现出色,大型语言模型却容易产生有害、误导和偏见的内容。作者评估了模型在不同安全基准上的性能并对模型进行的红队测试以识别可能的安全风险。
作者进行了三种安全基准的测试:TruthfulQA、ToxiGen和BOLD。
- TruthfulQA:用于评估模型输出内容的事实性。该基准包括817个问题,覆盖38个不同领域,包括健康、法律、财务和政治。
- ToxiGen:用于测量模型输出的毒性,特别是针对13个少数群体的有毒和仇恨生成内容。
- BOLD:用于量化模型对不同人口群体的偏见程度。该数据集涵盖种族、性别、宗教、政治意识形态和职业等多个领域。
研究结果表明,指令微调模型在与其他开源模型(如Falcon-instruct和MPT-instruct)以及专有模型(如GPT-3.5, GPT-4)比较时,具有相对较高的安全性和较低的偏见。
此外,为了进一步评估模型在长上下文场景中的安全性,作者还进行了红队测试(一种安全评估方法,用于识别组织信息系统、网络或物理环境中存在的脆弱点)。测试的主要目的是通过提供长篇上下文和敌对提示来尝试攻击模型,这些提示涵盖了多个风险领域,如非法行为、恶意行为和提供不合格的建议。结果表明,与其他模型(如LLAMA 2 CHAT)相比,这些指令微调模型没有显示出明显的安全风险。
限制
随着论文提出的模型很厉害,但还是存在一些限制:
- 功能限制:本文提出的模型还未针对广泛的长上下文应用进行细致调优,比如需要长篇输出的创意写作。现有的对齐方法,比如 RLHF,应用在不同场景下成本高且非常复杂。甚至熟练的标注人员也可能难以应对密集文本中的错综复杂的细节。在这方面,我们认为,开发针对长 LLMs 的高效对齐方法是未来研究的有价值方向。
- 分词器效率:尽管此模型系列能处理多达 32,768 个 token 的上下文,但实际上模型能处理的单词数量很大程度上受到分词器行为的影响。Llama 系列的分词器词汇量较小(32k ),并且通常会产生比 GPT-3.5 的分词器更长的序列—我们发现我们的分词器通常平均多产生 10% 的token。此外,我们使用的分词器也不能有效处理空格,导致处理长代码数据的效率不高。
- 幻觉问题:和其他 LLMs 一样,我们在测试模型时也发现了幻觉问题。虽然短上下文模型常常面临这个问题,但长上下文模型由于消耗大量信息和对齐过程不足,解决这个问题的难度可能更大。
总结
总的来说,LLaMA 2 Long 对于大语言模型的长上下文问题的研究是非常振奋人心的,从实际测试结果上,在短上下文和长上下文任务上都超过了 LLAMA 2。与现有的开源长上下文模型相比,此模型表现也是更优的,并且在一套长上下文任务上,通过简单的指令微调程序(无人监督),它的表现也优于 gpt-3.5-turbo-16k 。
这篇论文一经发出,在网上如reddit、X上都引起了很多网友的讨论,有的不禁感叹 Meta is really on a roll.
也有对此表示质疑的。
目前官方还没有确切说明是否会发布这个版本,但最近大模型的迭代这么快,我想后续肯定还会不断有重磅的更新发出的!