如今国际上各种大语言模型蜂拥而至,但我们个人或者小公司想玩一个大模型要么花钱买硬件要么花钱买服务,因为大型语言模型(LLMs)虽然厉害,但部署起来非常困难!此外,这些巨型语言模型就像是那些吃不胖的人,吃了无数的数据,练了无数的参数,但是一到要“出门”工作的时候,问题来了。它们需要的计算资源和内存就像是一个永无止境的黑洞,让人望而却步。

今天我要讲的这篇论文给了我们一个非常棒的解决方案。简单来说,它教会了我们如何用更小的模型和更少的数据去击败这些庞然大物。这篇论文叫做 Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes,是由华盛顿大学联合谷歌共同发表,作者们提出了一种新的蒸馏机制「分步蒸馏」(Distilling Step-by-Step),旨在用更少的训练数据训练出性能超过LLMs的更小模型。
在实践中,部署大型语言模型(LLMs)很困难,主要是因为它们既不节省内存也不高效地执行计算。为了解决这一问题,研究人员通常会采用微调或蒸馏的方式来培训更小、更专业的模型。但这两种方法都需要大量的数据,才能达到与大型模型相似的效果。我们提出了一种新的解决方案,名为“逐步蒸馏”,它不仅能用更少的数据训练出比大型模型更高效的小型模型,还能在多任务环境中有效地应用。在四个不同的自然语言处理基准测试中,我们的方法都展示了出色的性能。具体来说,与现有的微调和蒸馏技术相比,我们的方法需要更少的数据就能获得更好的结果。此外,与只用少量样本进行训练的大型模型相比,我们的小型模型表现得更出色。最重要的是,我们证明了即使在数据有限的情况下,经过适当调整的小型模型也能超过大型模型的性能。
逐步蒸馏(Distilling step-by-step)
简单来说,逐步蒸馏就是用大型语言模型(LLMs)生成的“合理解释”来训练一个更小的模型。这样,小模型就能学习到大模型的“智慧”,但却没有大模型的“负担”。想象一下,你有一个巨大的图书馆(LLMs),里面有各种各样的书籍和信息。但是,你不能把整个图书馆都搬到你家里,对吧?逐步提炼就是找出图书馆中最重要、最有用的信息,并把它们放到一个小书架(小模型)上。
这篇论文的一个很酷的点是,它不仅把大型语言模型(LLMs)看作是一个生成标签的机器,还把它看作是一个能进行推理的“智者”。就像是你的智慧长者,不仅告诉你答案,还会告诉你为什么这是答案。这意味着,我们不仅要从大模型那里获取答案(或标签),还要理解这些答案是如何产生的。这就像是不仅要知道1+1=2,还要知道为什么是这样。
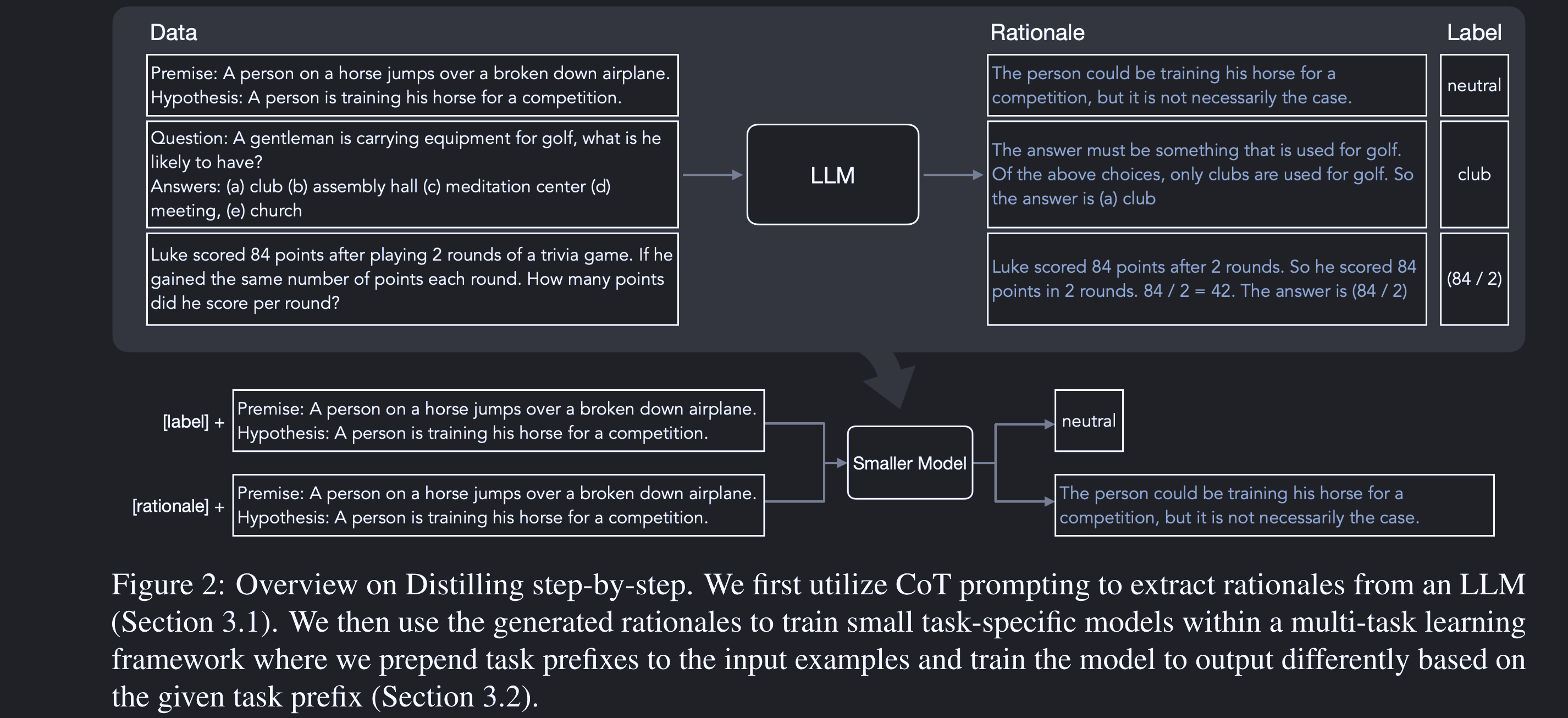
那么如何实现这个方法呢?总的来说分为2个步骤:
- 提取合理解释(rationale)
首先,我们要从大型语言模型(LLMs)那里获取一些“合理解释”。这听起来有点像是从巨人那里偷走魔法石,但实际上是通过一种叫做“Chain-of-Thought(CoT)”的提示来实现的。这个提示能让大模型告诉我们它是如何得出答案的。这个过程有点像是在进行一次心灵对话。你问大模型一个问题,它不仅给你一个答案,还给你一个解释。这个解释就是我们需要的“合理解释”。
- 训练更小的下游模型
有了这些“合理解释”,我们就可以开始训练我们的小模型了。这个过程就像是在教一个小孩子如何成为一个英雄。我们不仅给他任务(标签),还给他一些智慧(合理解释),这样他就能更快地学习和成长。这里的关键是,我们不仅用标签来训练小模型,还用合理解释来训练它。这就像是在教育一个孩子时,不仅教他知识,还教他如何思考。
实验
为了证明这个方法的有效性,作者选择了四个流行的NLP基准数据集:e-SNLI、ANLI、CQA和SVAMP,以及多种大小的T5模型进行实验。这些实验设计旨在解决两个主要问题:如何减少训练数据和如何减小模型大小。
减少训练数据
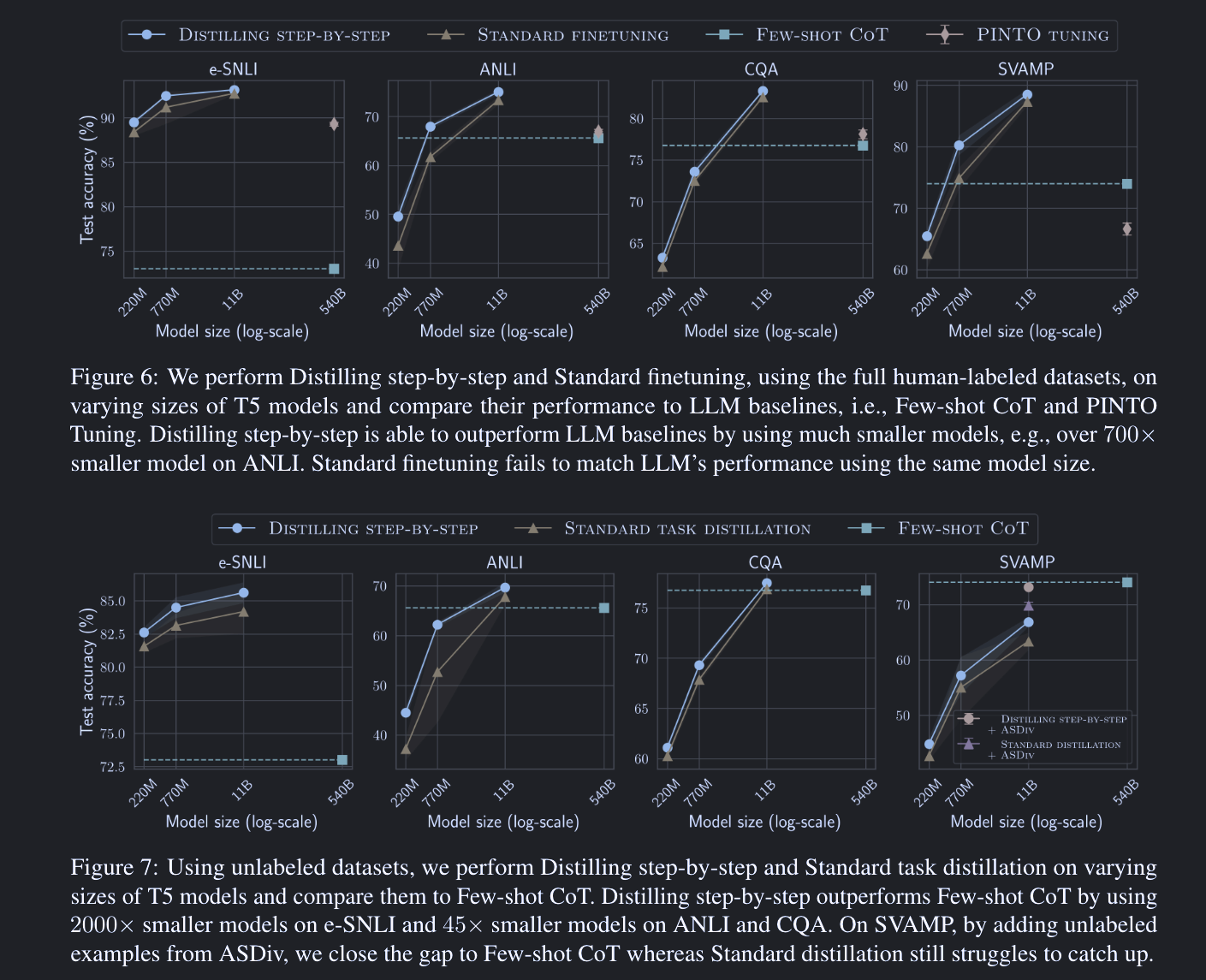
在这部分,作者比较了Distilling Step-by-Step与两种常见的任务特定模型学习方法:标准微调(Standard Finetuning)和标准任务蒸馏(Standard Task Distillation)。令人印象深刻的是,Distilling Step-by-Step在使用更少的标签样本时,能够实现比标准微调更好的性能。具体来说,在e-SNLI数据集上,仅使用12.5%的数据,其性能就超过了使用全部数据进行标准微调的性能。在ANLI、CQA和SVAMP数据集上,分别实现了75%、25%和20%的训练样本减少,同时仍然超过了标准微调的性能。

减少模型大小
这部分的实验结果同样令人印象深刻。与Few-shot CoT和Pinto Tuning两种基线方法进行比较。即使模型大小减小为770M(T5-Large),Distilling Step-by-Step也能达到或超过540B PaLM模型的性能。
消融研究
除了主要实验外,为了理解Distilling Step-by-Step框架中不同组件和设计选择的影响,论文还进行了消融研究,研究了从不同LLMs提取rationales的有效性以及比较了多任务训练方法与其他潜在设计选择。
最终,Distilling Step-by-Step在所有四个数据集上都超过了大型语言模型的性能。例如,在e-SNLI数据集上,其性能达到了89.51,而540B PaLM模型的性能为89.12。
如何应用?
首先,这种方法特别适合那些资源有限但又需要高性能模型的项目。比如,如果你是一个初创公司,没有大量的资金去购买超级计算机,那么这个方法就是你的救星。
想象一下,你只需要一个普通的笔记本电脑和一些基础的编程知识,就能训练出一个性能超强的模型!这不仅能节省你的时间,还能节省你的钱。
当然,没有哪个方法是完美的。这个方法也有它的局限性。比如,它可能不适用于所有类型的任务。但好消息是,这个方法是非常灵活的,你可以根据你的需要进行调整。比如,如果你发现合理解释不够准确,你可以尝试使用不同类型的提示或者更多的数据来改进它。这个方法的最大优点就是它的高效性和灵活性。你可以用它来解决各种各样的问题,而不需要担心资源问题。
但它也有缺点,比如它可能需要一些专门的调整才能达到最佳效果。但总体来说,它的优点远远大于缺点。
