Abstract
我们呈现了一套能处理高达 32,768 个token的长上下文语言模型(LLMs)。这些模型是基于 LLAMA 2 通过持续预训练而得,利用了更长的训练序列,并在一个长文本被放大采样的数据集上进行训练。我们对这套模型进行了全面评估,包括语言建模、合成上下文探测任务和多种研究基准测试。在研究基准测试中,我们的模型在大部分常规任务上都取得了一致的进步,而在面对 LLAMA 2 的长上下文任务时,改进更为显著。值得一提的是,通过一种不需要人工标记长指令数据的高效指令调优方法,70B 版本的模型已经能超越 gpt-3.5-turbo-16k 在长上下文任务集合上的总体表现。除了这些成果,我们还深入分析了我们方法的各个组件。我们探讨了 LLAMA 的位置编码,并讨论了它在处理长期依赖关系时的局限性。我们还研究了预训练过程中各种设计选择的影响,包括数据组合和序列长度的训练课程安排 – 我们的削减实验显示,预训练数据集中丰富的长文本并非实现优异性能的关键,通过实验证实,与从头开始使用长序列进行预训练相比,长上下文的持续预训练更高效且效果相近。

1. Introduction
大型语言模型(LLMs),经过前所未有的海量数据和计算能力的训练,展现了彻底改变我们与数字世界互动方式的潜力。随着 LLMs 的快速应用和持续扩展,我们期待这些模型能够应对更为精细和复杂的应用场景,例如分析知识密集型文档,打造更为真实且吸引人的聊天机器人体验,以及在编程和设计等迭代创作过程中辅助人类用户。支撑这种进步的核心特性是能够有效处理长篇幅输入的能力。
然而,目前具有强大长篇幅处理能力的 LLMs 主要通过专有的 LLM APIs(Anthropic, 2023; OpenAI, 2023)来提供,并没有公开的构建长篇幅模型的方法,能够展示与这些专有模型相匹敌的下游应用性能。此外,现有的开源长篇幅模型(Tworkowski 等人,2023b; Chen 等人,2023; Mohtashami 和 Jaggi,2023; MosaicML,2023b)在评估时常常表现不佳,它们主要通过语言建模损失和合成任务来衡量长篇幅处理能力,但这无法全面展示它们在多种真实世界场景中的有效性。同时,这些模型往往忽略了在标准短篇幅任务上保持高性能的重要性,或是直接跳过了评估,或是报告了性能下降(Peng 等人,2023; Chen 等人,2023)。
在此项研究中,我们展示了如何构建性能超越所有现有开源模型的长上下文语言模型(LLMs)。我们的模型是通过连续从 LLAMA 2 的检查点预训练,并额外添加了 4000 亿个长训练序列的标记来构建的。在这些模型中,较小的 7B/13B 版本是用 32,768 个标记的序列训练的,而 34B/70B 版本则是用 16,384 个标记的序列训练的。与之前的研究只进行了有限的评估不同,我们对模型进行了全面的评估,包括语言建模、合成任务,以及一系列覆盖长短上下文任务的实际基准测试。在语言建模方面,我们的模型展示了明显的与上下文长度相关的幂律缩放行为。如图 1 所示,这不仅表明我们的模型能够持续从更多上下文中受益,也暗示了上下文长度是缩放 LLMs 的重要方面。与 LLAMA 2 在研究基准上的比较显示,我们的模型不仅在长上下文任务上有显著的改进,而且在常规的短上下文任务上也有适度的提升,特别是在编程、数学和知识基准测试中。我们尝试了一种简单且成本低的方法,对我们的长模型进行了指令微调,而无需任何人工注释数据。最终,我们得到了一个聊天模型,其在一系列涵盖问题回答、总结和多文档聚合任务的长上下文基准测试中,比 gpt-3.5-turbo-16k 表现得更强。
在接下来的部分,我们首先将展示一种持续的长上下文预训练策略以及一个轻量级的指令调优方法,随后详细呈现了在各种短上下文和长上下文任务上的结果。为了推动未来的研究,我们还附上了一部分分析,讨论了如何位置编码的设计、数据集长度的分布以及训练课程对最终性能的影响。最后,我们进行了负责任的安全评估,证实了我们的模型能够很好地保持原始 LLAMA 2 系列的安全性能。
2 Method
2.1 Continual Pretraining
随着序列长度的增加,训练过程中的计算负担也会因为二次方的注意力计算而显著增加。这正是我们采取持续预训练方法的主要原因。我们基于一个假设,即通过从短上下文模型开始持续预训练,能够学习到类似的长上下文能力,这一假设在 4.4 节通过比较不同训练课程得到了验证。为了实施持续预训练,我们几乎完全保留了原始的 LLAMA 2 架构,只是对位置编码做了必要的调整,以便模型能够处理更长的序列。同时,尽管稀疏注意力(Child 等人,2019)是个不错的选择,但考虑到 LLAMA 2 70B 的模型维度(h = 8192),我们选择不采用它,因为只有当序列长度超过 49,152(6h)个token时(Narayanan 等人,2021),注意力矩阵的计算和值聚合才真正成为计算的瓶颈。
位置编码:通过一些初步的实验,我们发现了 LLAMA 2 位置编码(PE)的一个核心问题,它阻止了注意力模块有效地处理远距离的token信息。为了解决这个问题,我们对 RoPE 位置编码(Su 等人,2022)做了一些简单但必要的修改,主要是减小了旋转角度(由超参数“基频 b”控制),以减轻对远距离token的衰减效应。在 4.1 节中,我们展示了这种简单方法在扩展 LLAMA 上下文长度上比同期的方法(Chen 等人,2023)更为优秀,并为其优势提供了理论解释。
数据组合:基于已修改的 PE 的模型,我们在 4.2 节进一步探讨了不同的预训练数据组合,以增强长上下文能力,包括调整 LLAMA 2 预训练数据的比例或加入新的长文本数据。我们发现,对于长上下文的持续预训练,数据质量通常比文本长度更为重要。
优化详情:我们保持每批次的token数量不变,增加序列长度,持续地预训练 LLAMA 2 的检查点。所有模型都在 100,000 步中总共训练了 400B token。有了 FLASHATTENTION(Dao 等人,2022),增加序列长度时的 GPU 内存开销几乎可以忽略,但我们在将 70B 模型的序列长度从 4,096 增加到 16,384 时,发现速度下降了约 17%。对于 7B/13B 模型,我们使用了 2e−5 的学习率,并配合了 2000 步的预热期的余弦学习率计划。而对于较大的 34B/70B 模型,我们发现降低学习率(1e−5)对于获得单调递减的验证损失非常重要。
2.2 Instruction Tuning
为 LLM 对齐收集人类示例和偏好标签是一个费时费力的过程(Ouyang 等,2022; Touvron 等,2023)。在处理长上下文场景时,这种挑战和成本更为明显,因为它们通常涉及到复杂的信息流和专业知识,例如处理密集的法律或科学文档,这使得即使对于有经验的标注者来说,标注任务也非常不简单。实际上,大多数现有的开源指令数据集(Conover 等,2023; Köpf 等,2023)主要由短样本组成。
在这项研究中,我们发现了一种简单且成本低的方法,它通过利用预先构建的大型多样化的短提示数据集,在长上下文基准上表现出意想不到的好效果。具体而言,我们使用了 LLAMA 2 CHAT 中使用的 RLHF 数据集,并通过 LLAMA 2 CHAT 本身生成的合成自我指导(Wang 等,2022)长数据对其进行了扩展,希望模型能通过大量的 RLHF 数据学习到各种技能,并通过自我指导数据将这些知识应用于长上下文场景。数据生成过程主要关注 QA 格式的任务:从预训练语料库中的长文档开始,我们随机选择一段内容,并提示 LLAMA 2 CHAT 根据文本内容编写问题-答案对。我们收集了长答案和短答案,并使用不同的提示。随后,我们还进行了一个自我评估步骤,提示 LLAMA 2 CHAT 验证模型生成的答案。对于生成的 QA 对,我们使用原始长文档(截断以适应模型的最大上下文长度)作为上下文来构造训练实例。
对于短指令数据,我们将其组合成 16,384 token的序列。对于长指令数据,我们在右侧添加填充token,以便模型能够单独处理每个长实例,而无需截断。尽管标准的指令调优仅计算输出token上的损失,但我们发现在长输入提示上也计算语言模型损失对于在下游任务上持续改进(第 4.3 节)是非常有益的。
3 Main Results
3.1 Pretrained Model Evaluation
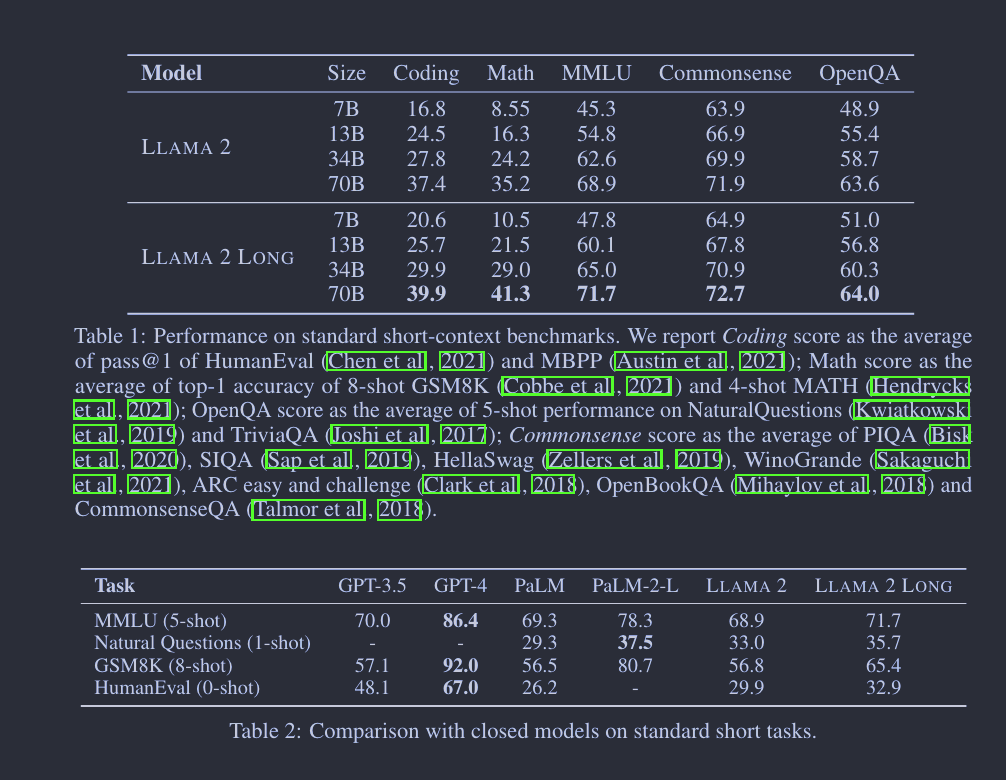
短任务: 为了让长上下文语言模型(LLMs)广泛应用,保持在标准短上下文任务上的出色表现是很重要的。依照之前的研究(Touvron 等人,2023),我们检验了我们模型在一系列常见基准测试上的表现。所有结果汇总在表1中。总的来看,我们发现在多数情况下,模型的表现与 LLAMA 2相当,甚至更好。特别是,在编程、数学和知识密集的任务如 MMLU 上,我们模型的表现有了明显提升。如表2显示,我们的模型在 MMLU 和 GSM8k 上超过了 GPT-3.5,这与先前一项观察到短任务表现下降的研究(Chen 等人,2023)形成鲜明对比。我们认为这种进步得益于额外的计算 FLOPs 和从新增的长数据中获取的知识。
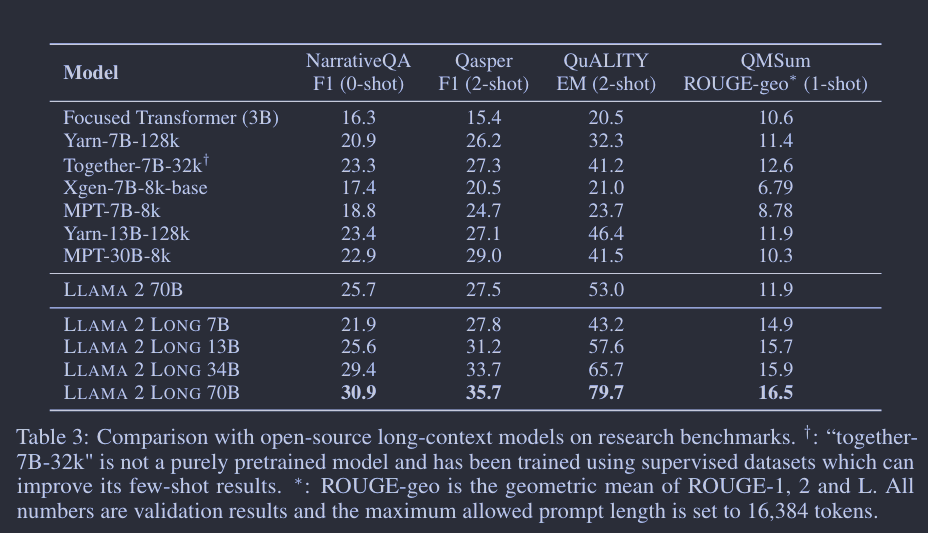
长任务: 与之前主要通过困惑度和合成任务来评估长上下文性能的研究(Chen 等人,2023;Mohtashami 和 Jaggi,2023)不同,我们采用了实际的语言任务来进行长上下文评估。我们在 NarrativeQA(Koˇciský 等人,2018)、QuALITY(Pang 等人,2022)、Qasper(Dasigi 等人,2021)和 QMSum(Zhong 等人,2021)上分别进行了0-shot、2-shot 和 1-shot 的评估。shot次数是基于每个数据集的平均样本长度确定的(例如,Qasper 和 QuALITY 中的样本通常比 NarrativeQA 中的样本短很多)。我们专注于这些问答风格的任务,因为它们易于进行提示设计2,且自动评估较为公正。如果提示超过模型的最大输入长度或16,384个token,输入提示会从左侧截断。我们将模型与 Huggingface Transformers 中可用的开源长上下文模型,如 Focused Transformer(Tworkowski 等人,2023a)、YaRN(Peng 等人,2023)、Xgen(Nijkamp 等人,2023)、MPT(MosaicML, 2023b,a)和 Together’s LLAMA 2fork(Together, 2023)进行了比较。如表3所示,我们的模型比这些模型表现更好。在7B规模上,只有“Together-7B-32k”能与我们的模型匹敌。值得注意的是,这个模型不是纯自监督模型,而是通过使用大型监督数据集进行微调以改善其少射击结果。由于我们模型的7/13B版本是与32ktoken序列一起训练的,我们还使用32,768最大提示长度进行了比较,结果如表13所示,是一致的。
有效利用上下文:为了证实我们的模型能有效使用扩大的上下文窗口,我们首先在图 2 中展现了,随着上下文长度的增加,每个长任务的结果都逐步提升。受到(Kaplan 等人,2020;Hoffmann 等人,2022)的启发,我们还发现我们的模型的语言建模损失与上下文长度之间呈现出幂律加常数的关系(图 1),这意味着:
- 尽管收益在递减,但我们的模型在性能上(特别是在语言建模损失方面)仍然能够展现出增益,直到文本token数量达到 32,768。以我们的 70B 模型为例,如果我们将上下文长度加倍,我们可以预期损失将以 2^−β ≈ 0.7 的因子减少,再加上一个模型特定的常数 (1 − 2^−β) · γ。
- 从曲线的较大 β 值可以看出,更大的模型能更有效地利用上下文。

3.2 Instruction Tuning Results
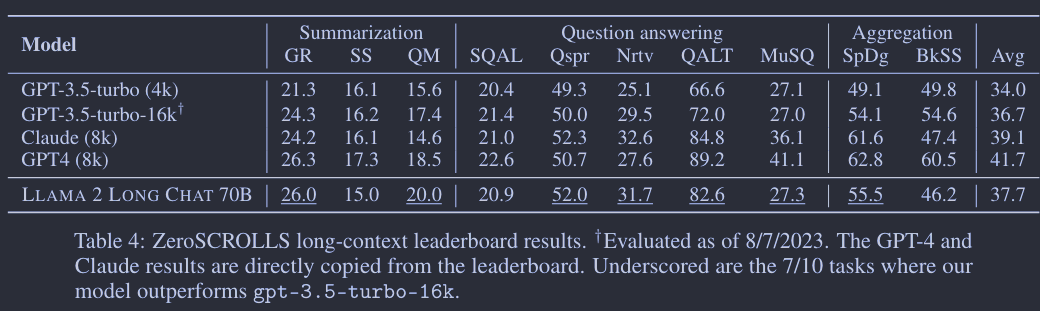
我们在 ZeroSCROLLS (Shaham 等人,2023)上测试了我们经过指令调优的模型,该测试包括10个涵盖摘要、问答和多文档聚合任务的长上下文数据集。为了公平比较,我们遵循了基准测试所指定的相同配置(如提示、截断策略和最大生成长度等)。如表4所示,即便没有使用任何人工标注的长上下文数据,我们的70B聊天模型在10个任务中的7个上都超过了 gpt-3.5-turbo-16k。此外,我们也在 LEval (An 等人,2023)中引入的六个新的长任务上进行了评估,再次得到了令人印象深刻的结果,详见附录中的表17。我们发现,经过微调的模型在问答任务上表现非常出色,这正是自我指令数据的主要主题。我们期望,如果用更多种类的数据进行微调,模型的表现会进一步提升。
值得一提的是,评估长上下文 LLMs 并非易事。这些基准测试中使用的自动指标在很多方面都存在局限,比如在摘要任务中,只提供了一个单一的基准摘要,而 n-gram 匹配指标并不一定能够反映人类的偏好。在问答和聚合任务中,虽然度量不是主要关注点,但截断输入上下文可能会去掉回答问题所需的信息。另一个要注意的问题是,大多数私有模型都没有共享它们的训练数据细节,这使得在公共基准测试评估时很难考虑到潜在的数据泄漏问题。
3.2 Human Evaluation
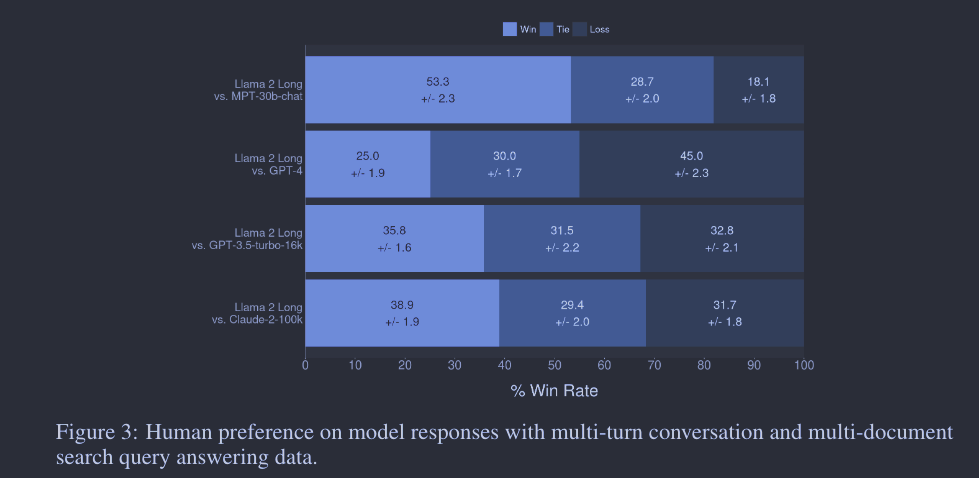
除了自动评估的基准测试结果外,我们还进行了人工评估,询问注释员他们更倾向于我们指令微调模型的生成,还是更喜欢像 MPT-30B-chat、GPT-4、GPT-3.5-turbo-16k 和 Claude-2 这样的专有模型在帮助度、诚实度和安全性方面的表现。不像自动评估,人类更擅长于评价长上下文模型的回应质量,因为可接受的答案空间非常广泛。我们主要关注了两大应用场景,共有 2,352 个样例。在多轮对话的数据中,每个提示都是基于聊天历史,模型需要据此生成连贯的回应。在多文档搜索查询回答应用中,模型会得到从搜索会话中检索到的几篇最相关的文档和相应的搜索查询。接着我们评估了这些模型如何利用这些信息(检索到的文档)来回答给定的查询。每个比较样例都由 3 名不同的人类注释员评估。通过平均每个比较样例的结果,我们计算了我们的模型相对于每个模型的标准胜率,并在图 3 中展示了最终得分以及 95% 的置信区间。尽管只有很少的指令数据,我们的模型仍能与 MPT-30B-chat、GPT-3.5-turbo-16k 和 Claude-2 竞争,取得不错的性能。值得指出的是,对于长上下文任务的人类评估是具有挑战性的,通常需要经过良好训练的、技能熟练的注释员。我们希望这项研究不仅能展示我们的指令微调模型在一些长上下文下游应用上的潜力,还能推动未来在开发更为健壮的长上下文自动评估方面的努力。
4. Analysis
在这个章节中,我们通过 ablation experiments 来验证我们的设计选择(如架构的修改、数据组合和训练课程设计)并量化这些选择对最终性能的贡献。
4.1 Positional Encoding for Long Text
我们初期的试验采用了一个名为“FIRSTSENTENCE-RETRIEVAL”的模拟任务,以检测预训练模型对上下文窗口的有效理解,简单地让模型返回输入的第一句。初始结果显示,即便在进行了大量长上下文连续预训练后,保留原始 LLAMA 2 架构的我们的模型仍然不能有效地处理超过 4,000 – 6,000 个token。我们推测,这个瓶颈来自 LLAMA 2 系列中使用的 ROPE 位置编码,它对远距离token的注意力分数产生了显著的衰减。我们提出了一个简单的调整,把 ROPE 的“基频 b”从 10,000 提高到 500,000,基本上减小了每个维度的旋转角度。这个想法同时也在 Reddit r/LocalLLaMa 社区和 Rozière 等人(2023)的研究中被提出。基频变更的效果在图 4 中得以可视化。另外,名为“位置插值”(PI)(Chen 等人,2023)的并行方法提出线性缩放输入位置,使长序列中的token位置能匹配到模型的原始位置范围,如图所示,它也隐式地实现了衰减减少效果。
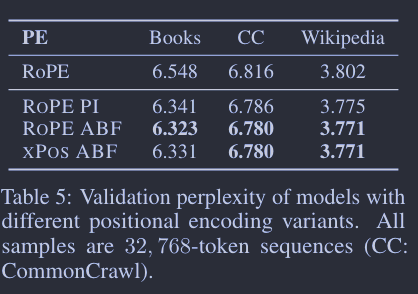
另一个从可视化中得出的有趣发现是,ROPE 在长范围区域产生了大的“振荡”,对于语言模型可能不是理想的(Sun 等人,2022)。为了探究这种效应是否影响性能,我们也探索了另一个最近提出的旋转编码变体,XPOS(Sun 等人,2022),它能够平滑高频组件。需要注意的是,具有默认参数的 XPOS 也面临与 ROPE 相同的衰减问题,因此我们也对 XPOS 应用了类似的衰减修复。
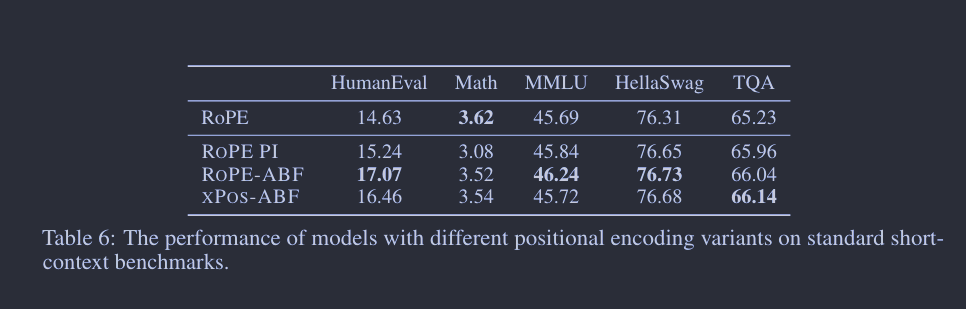
具体而言,我们通过实证比较了以下几种方法:ROPE 基线、PI、我们提出的调整基频的 ROPE(简称 ROPE ABF)以及 XPOS ABF(图 4 有视觉比较)。我们在 1)图 5 和图 5a 的长序列验证困惑度,2)图 5b 的 FIRST-SENTENCE-RETRIEVAL 上下文探测任务,以及 3)表 6 的一些典型的常规上下文任务(以验证长模型在短上下文任务上的表现不会下降)上报告了结果。所有的模型变体都是从 7B LLAMA 2 检查点开始,通过额外的 80B token,组织为 32,768 token的长序列,进行持续预训练。
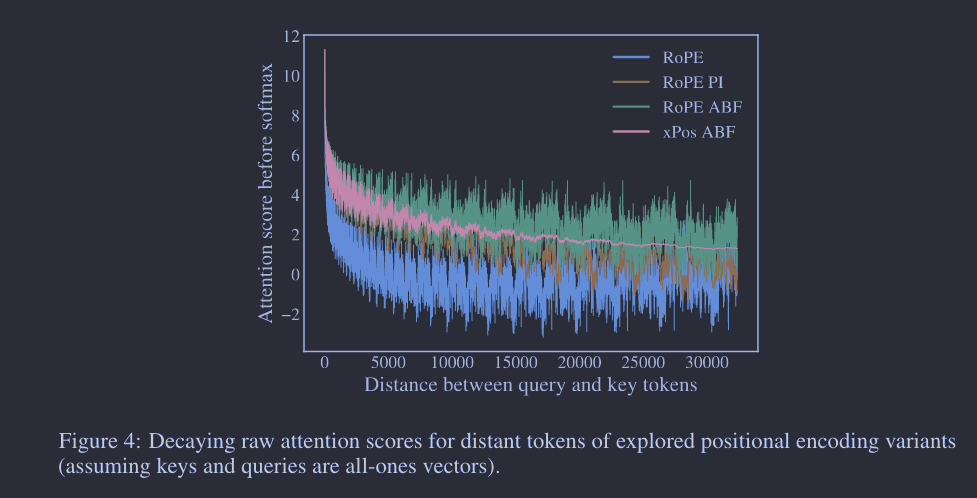
总的来说,评估结果表明 ROPE ABF 在所有探索的变体中表现最优。特别是,在 FIRST-SENTENCE-RETRIEVAL 任务上,只有 ROPE ABF 能够保持其性能,直到完整的 32,768-token 的上下文窗口。我们还发现,震荡较少的 XPOS ABF 并没有带来明显的改进,这暗示这些异常现象对语言建模并无负面影响。虽然 XPOS 被认为具有较好的外推性(Sun 等人,2022),但我们发现,通过基频的调整,XPOS 的外推能力并不比 ROPE 好(见附录 C)。除了实证结果,我们还在附录 B 中提供了 RoPE ABF 的理论分析以及它与 PI 的不同之处。我们认为,与 RoPE PI 相比,RoPE ABF 以更细的粒度分布了嵌入向量,使得模型更容易区分不同的位置。值得一提的是,嵌入向量之间的相对距离与 RoPE PI 的关键参数呈线性关系,而与 RoPE ABF 的关键参数呈对数关系,这与我们的实证发现相吻合,即基频不是非常敏感,可以根据最大序列长度轻松调整。
4.2 Pretraining Data Mix
我们持续预训练模型所使用的数据是 LLAMA 2 已有数据集和新的长文本数据的结合。同时,我们调整了数据源的配比,以提高长文本样本的权重。我们早期的实验显示,使用这种数据混合方法能明显改善长上下文任务的表现,如表 7 的前两行所示。在本节,我们希望严格探讨这些改进的来源,特别是想区分数据长度分布和语料库质量本身的影响。
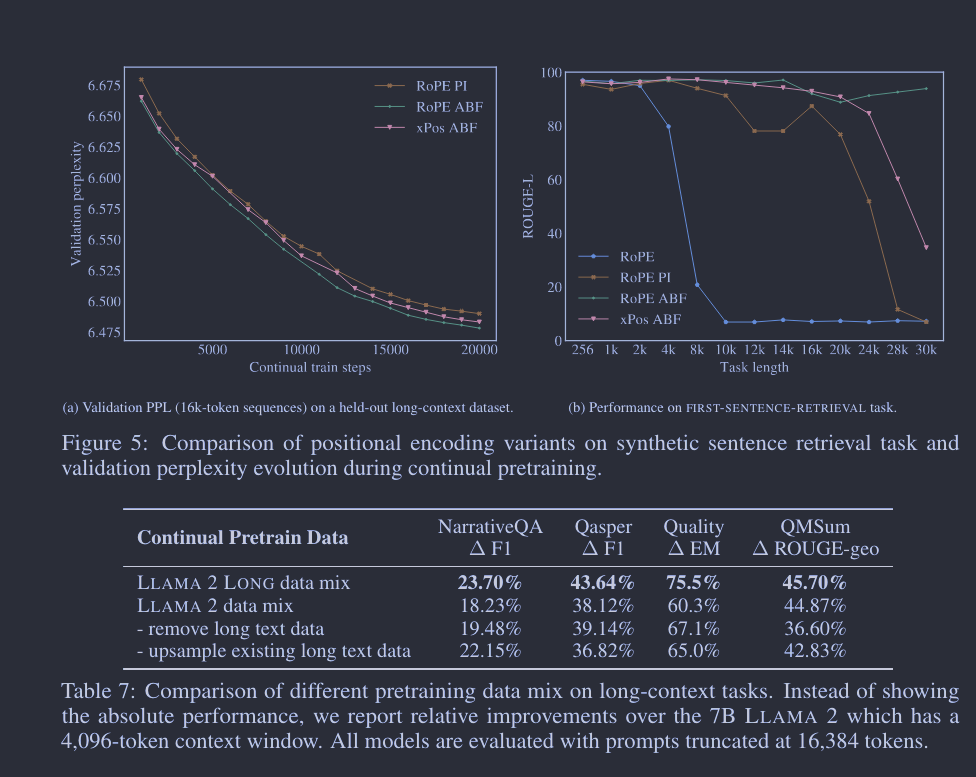
我们进行了两个附加的消融实验:1) 从 LLAMA 2 数据集中去除长文本数据,主要用短文档持续预训练模型;2) 增加现有长文本数据的样本权重,以匹配新模型所使用的长文本比例。有趣的是,即便去除了大部分长文本,模型仍能获得大部分相对于 LLAMA 2 的性能提升。我们还发现,即使大幅提高长数据比例(如表 7 和表 8 的第三行与第四行所示),也没有明显的优势。在附录的图 7 中,我们在 FIRST-SENTENCE-RETRIEVAL 任务上得到了类似的结果。
通过这些消融实验,我们发现调整预训练数据的长度分布并不带来主要好处。但在评估这些模型变体在标准短上下文任务上的表现时,我们发现新的数据混合在许多情况下确实带来了很大的改进,特别是在知识密集型任务如 MMLU 中,如表 8 所示。这些结果显示,即使长文本数据非常有限,长上下文 LLMs 也能得到有效的训练,而我们预训练数据的改进主要源自数据本身的质量,而非长度分布的差异。

4.3 Instruction Tuning
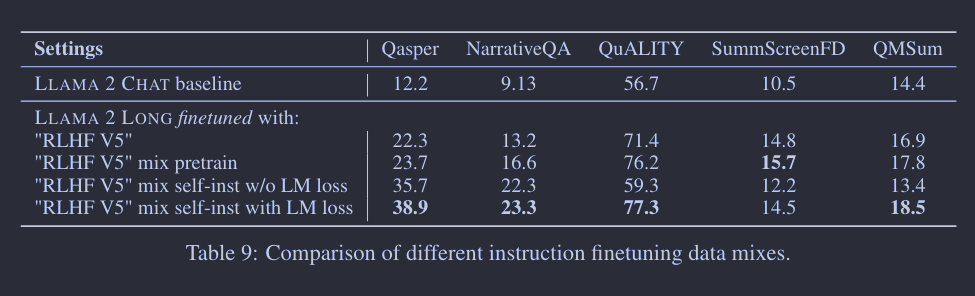
我们尝试了多种不同的策略来微调预训练过的长上下文模型,而这些策略不需要任何监督式的长数据。起初,我们仅用来自 LLAMA 2 CHAT 的短指令数据(在(Touvron et al., 2023)中被称为 “RLHF V5”)来微调模型,然后逐渐融入一些预训练数据,以避免忘记前面长上下文持续预训练的内容。如表 9 所示,仅仅通过短指令数据微调,就已经能够生成一个表现不错的长模型,该模型在很多长上下文任务上都明显优于 LLAMA 2。基于这个只包含短提示的数据集,我们发现添加预训练数据(即在整个序列上计算语言模型的损失)能进一步提升在大多数数据集上的性能。受此启发,当我们使用自指令数据微调时,我们也在长上下文输入上添加了语言模型损失。这个简单的小技巧在处理不平衡的输入输出长度时,使得学习过程更为稳定5,从而在大多数测试任务上都取得了显著的进步(见表 9 的最后两行)。
4.4 Training Curriculum
我们的实验已经展示了持续预训练的效果,但仍有一个悬而未决的问题:与持续预训练相比,从头开始用长序列进行预训练是否能够带来更好的性能?在这一部分,我们探讨了不同的训练课程,试图查明持续预训练是否能在较低的计算预算下提供具有竞争力的性能。首先,我们从头开始预训练了一个 7B 模型,其序列长度为 32,768。接着,我们尝试了不同的两阶段训练课程,开始时序列长度为 4096,然后在模型完成整个训练过程的 20%,40%,80% 时,将序列长度切换到 32,768。在所有这些情况下,我们保持总训练token数量不变,并通过相应调整批次大小和序列长度来确保每次梯度更新的token数量保持在 4 百万。
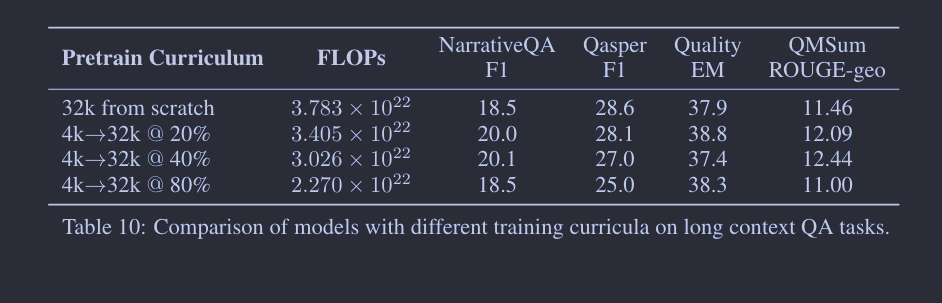
我们利用 4.2 节中用到的长文本 QA 任务来评估模型,并报告了最终模型在不同验证集上的困惑度。如表 10 和表 11 所示,通过从短上下文模型开始的持续预训练,我们可以轻松节省大约 40% 的 FLOPs,而性能几乎没有损失。这些结果与我们在图 6 中观察到的训练损失曲线相符,显示出模型能快速适应增加的序列长度,并达到相似的损失水平。

5. AI Safety
5.1 Evaluation on Safety Benchmarks
虽然在不同下游任务上表现出色,大型语言模型却容易产生有害、误导和偏见的内容(Lin 等人,2021; Hartvigsen 等人,2022; Dhamala 等人,2021; Ji 等人,2023)。长上下文语言模型能处理它们上下文窗口中的扩展输入,但同时也面临着更高的安全风险,特别是通过提示注入(Greshake 等人,2023)等手段。在这一节中,我们类似于(Touvron 等人,2023),通过使用 TruthfulQA(Lin 等人,2021)、ToxiGen(Hartvigsen 等人,2022)和 BOLD(Dhamala 等人,2021)三个标准学术基准来评估指令微调模型的安全性能。我们关注的是最大的指令微调模型变种(即 70B),并将其结果与表 12 中的开源 LLMs(如 Falcon-instruct 和 MPT-instruct)和专有的 LLMS(如 GPT-3.5, GPT-4(OpenAI, 2023), Claude-2 (Anthropic, 2023))进行比较。
我们发现,一般来说,指令微调模型保持了与 LLAMA 2 CHAT 相似的安全性能,并且相对于其他开源 LLMs,如 Falcon-instruct 和 MPT-instruct,更为安全且偏见更少。AI 安全是一个复杂的领域,使用三个基准全面评估指令微调模型的所有安全方面可能极为困难。不过,我们希望我们的分析能作为一个初步研究,为长上下文大型语言模型的安全性能提供方向性的指示,这在同一主题的其他作品中并未讨论过(Tworkowski 等人,2023b; Ding 等人,2023; Chen 等人,2023)。目前,社区还缺乏专门用于评估长上下文大型语言模型的安全基准,我们计划在未来的工作中投资于这个方向。
TruthfulQA: 我们在 TruthfulQA(Lin 等人,2021)上评估指令微调模型,以基准其事实性。这个基准包括 817 个问题,覆盖 38 个类别,包括健康、法律、财务和政治(Lin 等人,2021)。类似于(Touvron 等人,2023),我们使用少量提示,带有 6 个随机 QA 对生成,然后利用两个微调过的 GPT-3 模型分类生成是否真实和有信息。我们在表 12 中报告了既真实又有信息的生成的百分比作为最终指标。
ToxiGen: 我们使用 ToxiGen(Hartvigsen 等人,2022)测量指令微调模型的毒性,我们检查针对 13 个少数群体的有毒和仇恨生成的百分比。按照(Touvron 等人,2023)的做法,我们过滤了标记者对目标人口群体意见不一致的提示。我们使用基于 RoBERTa(Liu 等人,2019)微调的默认 ToxiGen 分类器评估模型输出的毒性水平。我们在表 12 中报告了所有群体的有毒生成的百分比。
BOLD: 我们使用 Bias in Open-Ended Language Dataset (BOLD)(Dhamala 等人,2021)来量化模型对不同人口群体的偏见程度。这个数据集包括 23,679 个提示,提取自英文维基百科,涵盖五个领域,包括种族、性别、宗教、政治意识形态和职业,总共 43 个子群体。按照 Touvron 等人(2023)的做法,我们排除了属于印度教和无神论宗教子群体的提示,因为它们只有 12 和 29 个提示。在每个模型推断出生成后,我们利用 Valence Aware Dictionary 和 Sentiment Reasoner (VADER)(Hutto 和 Gilbert,2014)进行情感分析,得分范围在 -1 到 1 之间。正分对应于提示中提到的子群体的正面情感,反之亦然。接近 0 的情感分值表示中立情感,这是我们所期望的。我们在表 12 中报告 43 个人口群体的平均情感得分作为 BOLD 的最终指标。

5.2 Red Teaming Exercises
现在还没有专为长上下文理解制定的开源安全基准。为了保证模型在长上下文应用场景中的安全,我们内部进行了红队测试,以更好地了解我们聊天模型的可能脆弱点。我们通过给模型提供长篇上下文(如长篇对话),然后用涵盖多个风险领域的敌对提示来尝试攻击模型,这些领域包括非法和犯罪行为(如恐怖主义、盗窃和人口贩卖)、恶意和有害行为(如诽谤、自我伤害、饮食失调和歧视)及不合格的建议 Touvron et al. (2023)。通过人工检查,我们发现相比于 LLAMA 2 CHAT Touvron et al. (2023),我们的模型没有显现出明显的风险。在未来的工作中,我们计划加大投入,探索针对长上下文大型模型的新的攻击向量。
6. Limitations
- 功能限制:本文提出的模型还未针对广泛的长上下文应用进行细致调优,比如需要长篇输出的创意写作。现有的对齐方法,比如 RLHF,应用在不同场景下成本高且非常复杂。甚至熟练的标注人员也可能难以应对密集文本中的错综复杂的细节。在这方面,我们认为,开发针对长 LLMs 的高效对齐方法是未来研究的有价值方向。
- 分词器效率:尽管我们提出的模型系列能处理多达 32,768 个token的上下文,但实际上模型能处理的单词数量很大程度上受到分词器行为的影响。Llama 系列的分词器词汇量较小(32k 符号),并且通常会产生比 GPT-3.5 的分词器更长的序列—我们发现我们的分词器通常平均多产生 10% 的token。此外,我们使用的分词器也不能有效处理空格,导致处理长代码数据的效率不高。
- 幻觉问题:和其他 LLMs 一样,我们在测试模型时也发现了幻觉问题。虽然短上下文模型常常面临这个问题,但长上下文模型由于消耗大量信息和对齐过程不足,解决这个问题的难度可能更大。
7. Conclusion
我们呈现了一系列长上下文语言模型(LLMs),这些模型通过简单但必要的位置编码优化和持续预训练,实现了出色的长上下文性能。我们的长上下文扩展是通过从 LLAMA 2 持续预训练并额外加入 400B token来完成,使得我们的模型在短上下文和长上下文任务上都超过了 LLAMA 2。与现有的开源长上下文模型相比,我们的模型表现更优,并且在一套长上下文任务上,通过简单的指令微调程序(无人监督)与 gpt-3.5-turbo-16k 表现堪比。我们还通过全面的分析补充了我们的结果,揭示了包括位置编码的微妙差异、数据组合和预训练课程等多种因素对最终性能的影响。我们希望我们的研究能使长上下文语言模型更为容易获得,并推动该领域的进一步进展。
8. Acknowledgement
我们要特别感谢 Nikolay Bashlykov、Matt Wilde、Wenyin Fu、Jiangyu Huang、Jenya Lee、Mathew Oldham 和 Shawn Xu 在项目的数据处理、基础设施建设和其他多方面的无私支持。