今天看了一篇来自于llmstack的创始人及CTO写的关于RAG的文章,正好最近在研究怎么玩本地知识库来着,感觉这篇文章很有帮助,这里翻译一下分享给大家,不过有时间的话更建议大家去看原文。
什么是检索增强生成?
如果你一直在向量存储或其他数据库中查找数据,并在生成输出时将相关信息作为上下文传递给 LLM,那么你已经在进行检索增强生成了。检索增强生成(简称 RAG)是 Meta 于 2020 年推广的一种架构,旨在通过将相关信息与问题/任务细节一起传递给模型来提高 LLM 的性能。
为什么选择 RAG?
LLM 是在大量语料库中训练出来的,可以回答任何问题或利用参数化记忆完成任务。这些模型有一个知识截止日期,具体取决于它们上次接受训练的时间。当被问及知识库之外的问题或知识截止日期之后发生的事件时,模型很有可能会产生幻觉。Meta 公司的研究人员发现,通过提供手头任务的相关信息,模型完成任务的性能会显著提高。
例如,如果模型被问及一个发生在截止日期之后的事件,那么提供该事件的相关信息作为上下文,然后再提问,将有助于模型正确回答问题。由于 LLM 的上下文窗口长度有限,我们只能传递与当前任务最相关的知识。我们在上下文中添加的数据的质量会影响模型生成的回答的质量。人工智能从业者在 RAG 管道的不同阶段会使用多种技术来提高 LLM 的性能。
RAG 与微调
微调是在特定任务上训练模型的过程,就像在问题解答数据集上微调 GPT-3.5 以提高其在特定数据集上的问题解答性能一样。如果你有一个足够大的数据集来完成手头的任务,而且数据集不会发生变化,那么微调就是一种很好的方法。如果数据集是动态的,我们就需要不断重新训练模型以跟上变化。如果手头的任务没有大型数据集,微调也不是一种好方法。在这种情况下,你可以使用 RAG 来提高 LLM 的性能。同样,你也可以使用 RAG 来提高 LLM 在摘要、翻译等任务上的性能,因为这些任务可能无法进行微调。
如何运行?
RAG 架构和管道包括三个主要阶段–数据准备、检索和生成。数据准备阶段包括确定数据源、从数据源中提取数据、清理数据并将其存储到数据库中。检索阶段包括根据手头的任务从数据库中检索相关数据。生成阶段包括利用检索到的数据和手头的任务生成输出结果。输出的质量取决于数据的质量和检索策略。下文将详细介绍每个阶段。
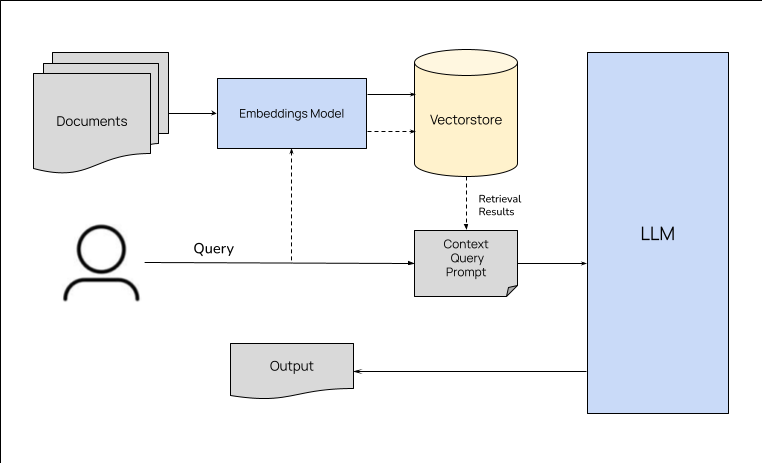
数据准备
根据 LLM 要处理的任务类型,数据准备通常包括确定数据源、从数据源中提取数据、清理数据并将其存储到数据库中。用于存储数据的数据库类型以及准备数据所涉及的步骤会因使用案例和检索方法的不同而不同。例如,如果你使用的是 Weaviate 这样的向量存储,你就需要为数据创建嵌入并将其存储到向量存储中。如果使用的是 Elasticsearch 等搜索引擎,则需要在搜索引擎中对数据进行索引。如果使用的是 Neo4j 等图数据库,则需要为数据创建节点和边,并将其存储在图数据库中。我们将在下一节讨论不同类型的数据库以及准备数据的步骤。
向量存储
向量存储用于存储文本、图像、音频等非结构化数据,并根据语义相似性搜索数据。嵌入模型用于为我们存储在数据库中的数据生成向量嵌入。根据数据类型、使用情况和嵌入模型,需要将数据分块成小块。例如,如果存储的是文本数据,可以将数据分块为句子或段落。如果存储的是代码,可以将数据分成函数或类。如果要为 LLM 提供广泛的上下文片段,可以使用更小的数据块。数据分块后,可以为每个分块生成嵌入,并将其存储在向量存储区中。当向向量数据库提出查询时,查询也会被转换为嵌入,向量存储库会返回与查询最相似的嵌入。
像 Weaviate 这样的向量数据库会在存储和检索过程中负责生成嵌入信息,你只需专注于数据建模和分块策略即可。
关键词搜索
关键字搜索是一种简单的数据检索方法,数据根据关键字编制索引,搜索引擎返回包含关键字的文档。关键字搜索适用于存储表格、文档等结构化数据,并使用关键字搜索数据。
图数据库
图形数据库以节点和边的形式存储数据。它们可用于存储表格、文档等结构化数据,并利用数据之间的关系搜索数据。例如,如果要存储有关人的数据,可以为每个人创建节点,并在相互认识的人之间创建边。当向图数据库提出查询时,图数据库会返回与查询节点相连的节点。这种使用知识图谱的检索方式对于问题解答等任务非常有用,因为问题解答的答案是一个人或一个实体。
搜索引擎
RAG 管道中的数据可以从谷歌、必应等公共搜索引擎或 Elasticsearch、Solr 等内部搜索引擎检索。在 RAG 架构的检索阶段,搜索引擎会被询问问题/任务的详细信息,然后搜索引擎会返回最相关的文档。搜索引擎对于从网络上检索数据和使用关键字搜索数据非常有用。来自搜索引擎的数据可与其他数据库(如向量存储、图形数据库等)的数据相结合,以提高输出的质量。
结合多种策略(如语义搜索 + 关键字匹配)的混合方法也是可行的,而且众所周知,对于大多数用例来说,混合方法能提供更好的结果。例如,你可以使用向量存储来存储文本数据,使用图数据库来存储结构化数据,然后将两个数据库的结果结合起来生成输出。
检索
一旦数据被识别和处理以备检索,RAG 管道就会根据所处理的任务(用户提出的问题)检索相关数据,并准备将上下文传递给生成器。检索策略可根据用例而有所不同。它通常涉及将用户的查询或任务传递给数据存储并提取相关结果。例如,如果我们正在使用一个存储相关数据块的向量数据库构建一个问题解答系统,那么我们可以为用户的查询生成嵌入式数据,在向量数据库中对嵌入式数据进行相似性搜索,然后检索出最相似的数据块(有些向量数据库会在检索过程中生成嵌入式数据)。同样,根据不同的使用情况,我们可以在同一向量存储区或多个数据库中进行混合搜索,并将搜索结果作为上下文传递给生成器。
生成
一旦检索到相关数据,就会连同用户的查询或任务一起传递给生成器(LLM)。LLM 使用检索到的数据和用户的查询或任务生成输出。输出结果的质量取决于数据的质量和检索策略。生成输出结果的指令也会对输出结果的质量产生很大影响。
提高 RAG 生产性能的技术
以下是 RAG 管道不同阶段的一些技术,可用于提高 RAG 在生产中的性能。
- 混合搜索(Hybrid search):众所周知,将语义搜索与关键字搜索相结合,从向量存储中检索相关数据,能为大多数使用案例提供更好的结果。
- 摘要(Summaries): 对数据块进行总结并将总结存储在向量存储中,而不是原始数据块,可能会有好处。例如,如果你的数据中包含大量填充词,那么最好对数据块进行总结,去除填充词,并将总结存储在向量存储中。这将提高生成质量,因为我们正在去除数据中的噪音,并有助于减少输入中的标记数量。
- 重叠块(Overlapping chunks): 在将数据分割成用于语义检索的数据块时,可能会出现语义搜索的情况,我们可能会选择一个在相邻数据块中有相关和有用上下文的数据块。在没有周围上下文的情况下,将该数据块交给 LLM 生成可能会导致输出质量不高。为了避免这种情况,我们可以将语块重叠,然后将重叠的语块交给 LLM 生成。例如,如果我们要将数据分割成 100 个词块,我们可以将这些词块重叠 50 个。这将确保我们将周围的上下文传递给 LLM 进行生成。
- 微调嵌入模型(Fine-tuned embedding models): 使用现成的嵌入模型(如 BERT、ada 等)为数据块生成嵌入模型可能适用于大多数用例。但如果你正在处理一个特定的领域,这些模型可能无法在向量空间中很好地代表该领域,从而导致检索质量低下。在这种情况下,我们可以对该领域的数据进行微调并使用嵌入模型,以提高检索质量
- 元数据(Metadata): 为上下文中传递的数据块提供来源等元数据,有助于 LLM 更好地理解上下文,从而生成更好的输出结果。
- 重排序(Re-ranking): 在使用语义搜索时,前 k 结果有可能彼此相似。在这种情况下,我们应该考虑根据元数据、关键词匹配等其他因素对结果进行重新排序,以便向 LLM 提供广泛的上下文片段。
- 中段遗失(Lost in the middle):据观察,LLMs 对输入中的所有词元的权重并不相同。位于中间的词元所占权重似乎低于输入开头和结尾的词组。这就是所谓的 "中段遗失 "问题。为了避免这种情况,我们可以对上下文片段重新排序,将最重要的片段放在输入的开头和结尾,而将不太重要的片段放在中间。
RAG in LLMStack
RAG 流程在LLMStack中开箱即用。当你创建数据源并上传数据时,LLMStack 会对数据进行分块、生成嵌入并将其存储到向量存储中。当你创建一个使用 Text-Chat 处理器的应用程序时,LLMStack 会负责从向量存储中检索相关数据,并将其传递给 LLM 进行生成。网站聊天机器人、人工智能增强搜索、品牌文案检查器等模板都使用了 LLMStack 中的 RAG 管道。
结论
事实证明,RAG 是一种简单而强大的方法,可用于提高 LLM 在各种任务中的性能。随着研究人员和从业人员不断改进 RAG 管道的各个阶段,我们有望在不久的将来看到更多的 RAG 应用案例。如果你有兴趣在工作中利用 RAG,可以登录 https://github.com/trypromptly/LLMStack 或使用我们的云产品 Promptly 试用 LLMStack。