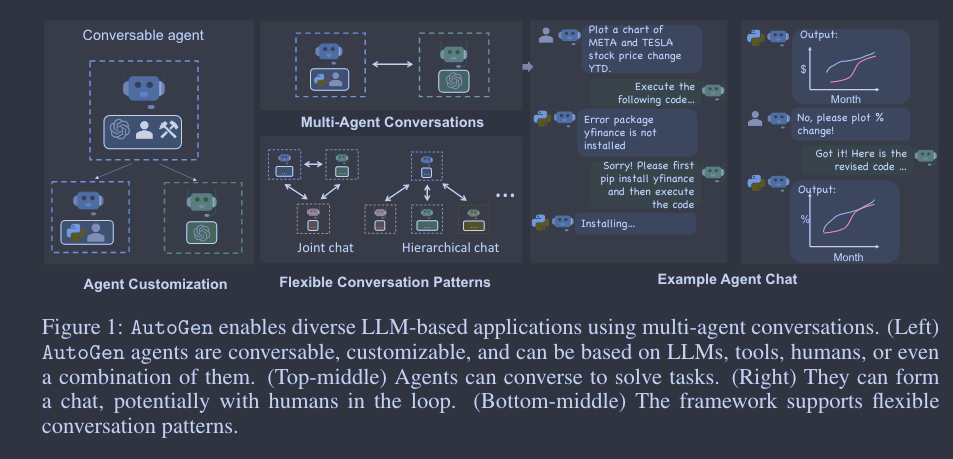
AutoGen 论文翻译(机翻)

摘要 AutoGen 是一个开源框架,允许开发人员通过多个代理构建 LLM 应用程序,这些代理可以相互对话以完成任务。AutoGen 代理是可定制的、可对话的,并能以各种模式运行,这些模式采用 LLM、人类输入和工具的组合。使用 AutoGen,开发人员还可以灵活定义代理交互行为。自然语言和计算机代码都可用于为不同应用编程灵活的对话模式。AutoG…
“你是Agent啊?巧了么不是?我也是!” — 多代理对话框架AutoGen介绍
如何让你的LLM能跟操作系统一样可以持久化记忆?
前几天我分享了一篇跟Agent研究有关的文章,文章最后说过我还有一篇想要分享的,今天我就给大家带来了,它就是 “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation”。 我们知道,LLM不仅能够生成文本,还能进行复杂的任务和计算。然而,尽管这些模型具有巨大的…
好久没更新论文的分享了,今天来给大家分享一篇最近阅读的个人感觉非常有价值的一篇:MEMGPT: TOWARDS LLMS AS OPERATING SYSTEMS。我们都知道无论是ChatGPT、LLaMA、Claude等等大模型,虽然支持结合上下文进行对话,但这个对话长度实际是受限的,尤其是如果想进行长文档处理的时候就更头疼了,那么对于大模型这种…

如何用更小的模型和更少的数据打败大型语言模型?
如今国际上各种大语言模型蜂拥而至,但我们个人或者小公司想玩一个大模型要么花钱买硬件要么花钱买服务,因为大型语言模型(LLMs)虽然厉害,但部署起来非常困难!此外,这些巨型语言模型就像是那些吃不胖的人,吃了无数的数据,练了无数的参数,但是一到要“出门”工作的时候,问题来了。它们需要的计算资源和内存就像是一个永无止境的黑洞,让人望而却步。 今天我要讲的…

Effective Long-Context Scaling of Foundation Models论文翻译(机翻)
Abstract 我们呈现了一套能处理高达 32,768 个token的长上下文语言模型(LLMs)。这些模型是基于 LLAMA 2 通过持续预训练而得,利用了更长的训练序列,并在一个长文本被放大采样的数据集上进行训练。我们对这套模型进行了全面评估,包括语言建模、合成上下文探测任务和多种研究基准测试。在研究基准测试中,我们的模型在大部分常规任务上都…

“羊驼”又双叒叕升级了!LLaMA 2 Long 正式来袭!
分享两篇大模型幻觉问题相关的论文
LLaMA 2 刚发布没多久,Meta又推出了它的升级版,LLaMA 2 Long正式登场!性能上全面超越LLaMA 2。和其他竞争对手相比也丝毫不弱,甚至能超越ChatGPT(3.5)。 目前虽然市面上已经有很多大语言模型(LLMs),但我们都知道它们都存在一个问题,就是处理长上下文的时候容易出现健忘和胡说八道的情况。目前我个人若需要处理长文本的…
最近看了两篇关于大模型幻觉问题的论文,一篇叫做 A Survey of Hallucination in “Large” Foundation Models,是关于大型基础模型(Large Foundation Models, LFMs)的幻觉问题的一个综述。另外一篇是来自MetaAI的 Chain-of-Verification Reduces …

人脸识别和神经风格迁移介绍
终于来到Andrew Ng教授深度学习专项课程CNN课程的的最后一节课的笔记博客了,这也是这门课程专栏的最后一篇博文了,本篇主要内容主要是CNN在人脸识别和神经风格迁移中的应用。那我们开始吧! 人脸识别 人脸识别简介 什么是人脸识别?我想大家应该都使用过人脸识别的系统,比如一些办公楼或者小区的人脸识别系统,系统可以识别到一个活生生的人脸(相比于照片…
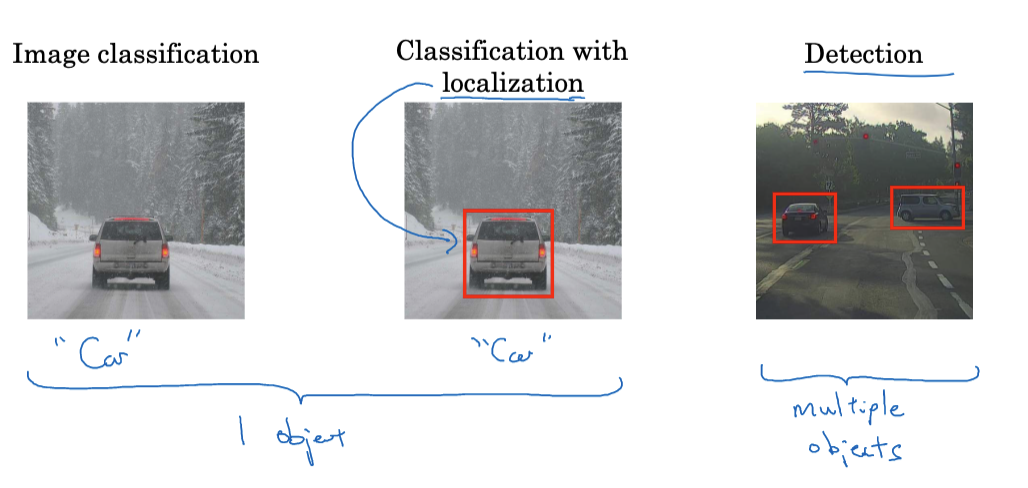
浅谈CNN中的检测算法
图像处理算法发展迅速,卷积神经网络扮演越来越重要的角色。本文基于Andrew Ng 教授的深度学习专项课程第四门课程的第三周内容来详细介绍卷积神经网络(CNN)中的主要检测算法,包括对象识别定位、如何提升检测精度,YOLO算法,语义分割等概念。 对象的识别与定位 计算机视觉的核心挑战之一是如何使机器能够“看到”和“理解”图像中的内容。不同于人类直观…
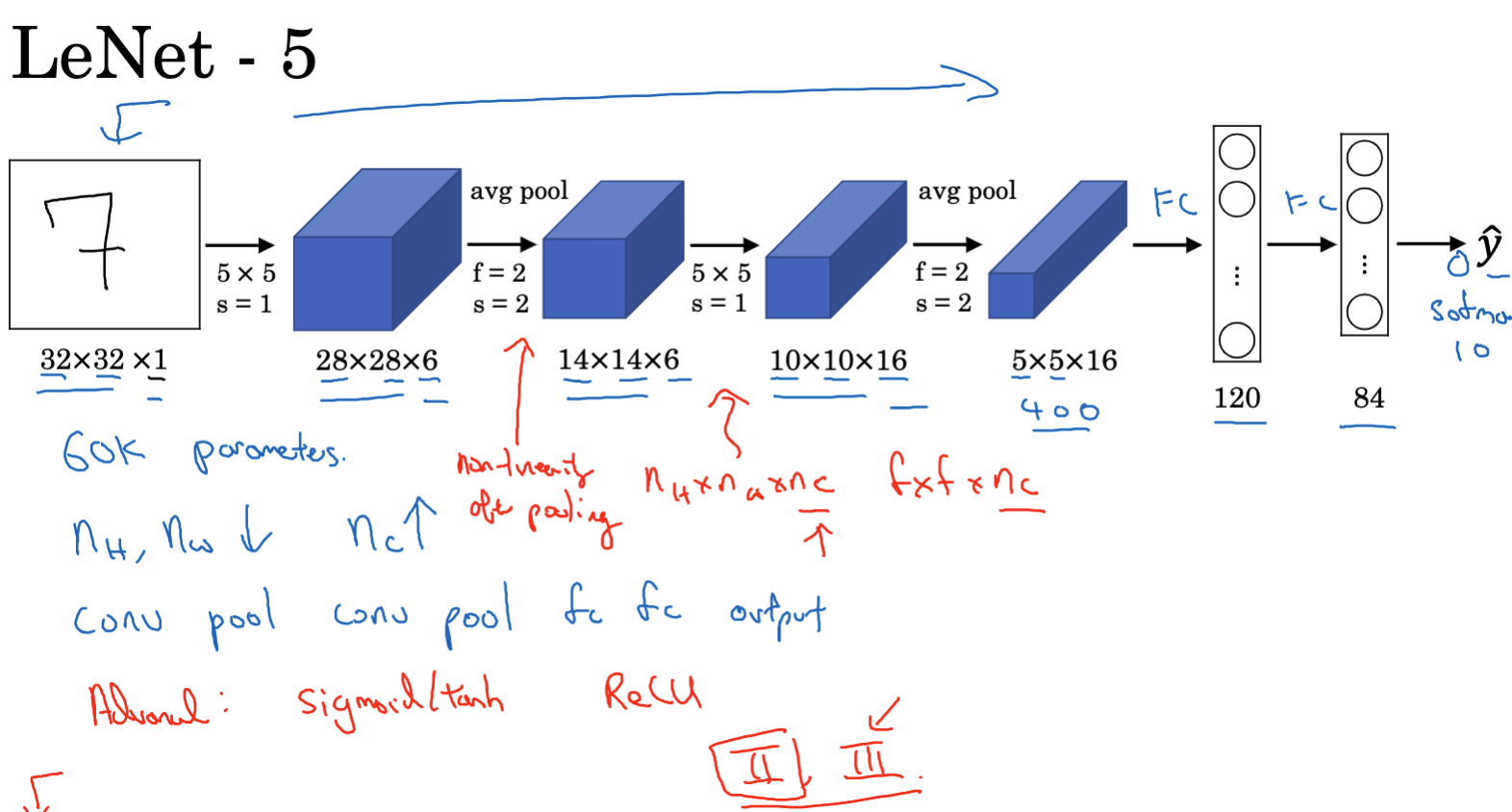
深度卷积神经网络案例研究
在深度学习快速发展的时代,各种创新型的神经网络架构层出不穷。要想跟着时代的发展,对于这些案例的研究是很有必要的。本篇博客将基于Andrew Ng教授的深度学习专项课程第四门课程的第二周内容来针对卷积神经网络的一些案例进行介绍。 案例研究的意义 首先思考一个问题,我们为什么需要研究这些案例呢? 首先,这些案例承载了前人在网络设计中积累的知识和经验。通…