OpenAI在自己的官方网站上之前发布了关于如何进行提示工程的指导文档,这份文档可以帮助我们更好的对AI发起提问,从而得到更有效的答案。以下是针对原文的翻译,主要使用ChatGPT4进行机翻,人工也会做一些微调,主要排版做了一点调整,此外有一些翻译不准确的地方请多见谅,但也希望大家看看原文,一起学习。本文主要提供的六个策略我这里直接列出来,方便大家…

不久前,NeurIPS 官方公布了 2023 年度的获奖论文,其中时间检验奖颁发给了10年前的论文「Distributed Representations of Words and Phrases and their Compositionality」。这篇论文可以看做是Word2Vec的第二篇论文。第一篇是「Efficient Estimatio…

长期潜水在各个LLM技术群的小透明今天看到了智谱AI和清华团队又整了一篇有意思的论文,叫做Black-Box Prompt Optimization: Aligning Large Language Models without Model Training 主要是解决大模型的"对齐问题"。 啥叫对齐问题呢?指的是确保人工智能(…
今天又看了一篇好玩的关于RAG玩法的论文,叫做 SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION 。 核心思想很有意思,让LLM自己对自己说的话反思反思(脑海里不由得就想起前不久某知名主播说的让我们反思的话了)。接下来我就大致介绍一下这个方法…
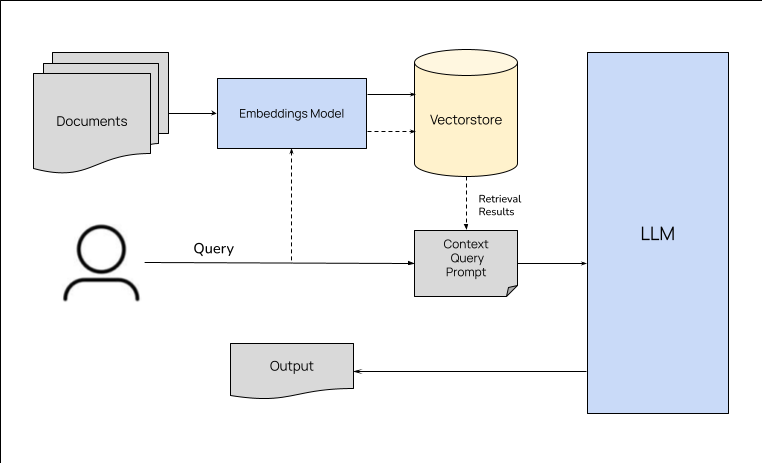
今天看了一篇来自于llmstack的创始人及CTO写的关于RAG的文章,正好最近在研究怎么玩本地知识库来着,感觉这篇文章很有帮助,这里翻译一下分享给大家,不过有时间的话更建议大家去看原文。 什么是检索增强生成? 如果你一直在向量存储或其他数据库中查找数据,并在生成输出时将相关信息作为上下文传递给 LLM,那么你已经在进行检索增强生成了。检索增强生成…
最近在研究如何将大语言模型结合本地知识库进行问答,虽然网上已经有很多教程,但大部分都是基于LangChain进行文本分割,然后调用模型向量化的API。这种方式的确很简单,但有这么几个前提: 大模型不使用ChatGPT的话,其实效果很差 尽管有多重切分方式,但还是很容易把文档中的一些语义撕裂。 由于众所周知的原因,使用ChatGPT的embeddin…
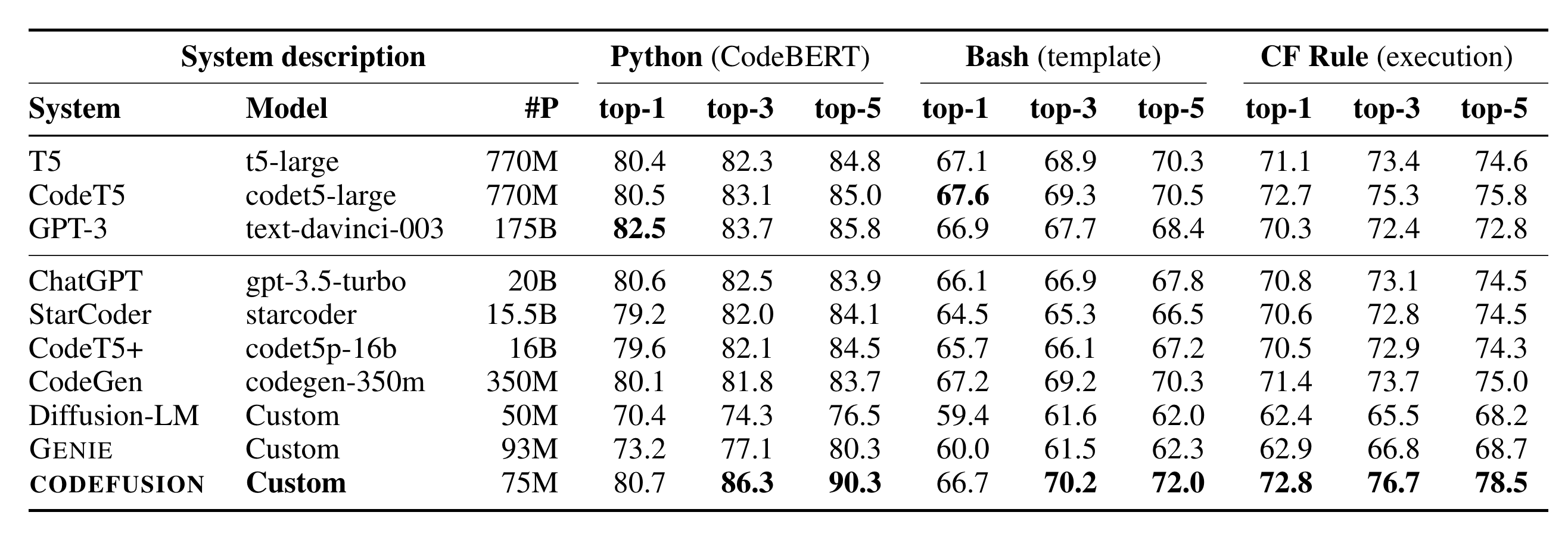
微软在10.26日发表了一篇论文CODEFUSION: A Pre-trained Diffusion Model for Code Generation,主要内容是提出了一个叫做CodeFusion的模型,它是一个基于扩散模型的从自然语言到代码生成模型,相对于论文提到的这个模型,更劲爆的是论文中的一张表格:看到图中的System descript…
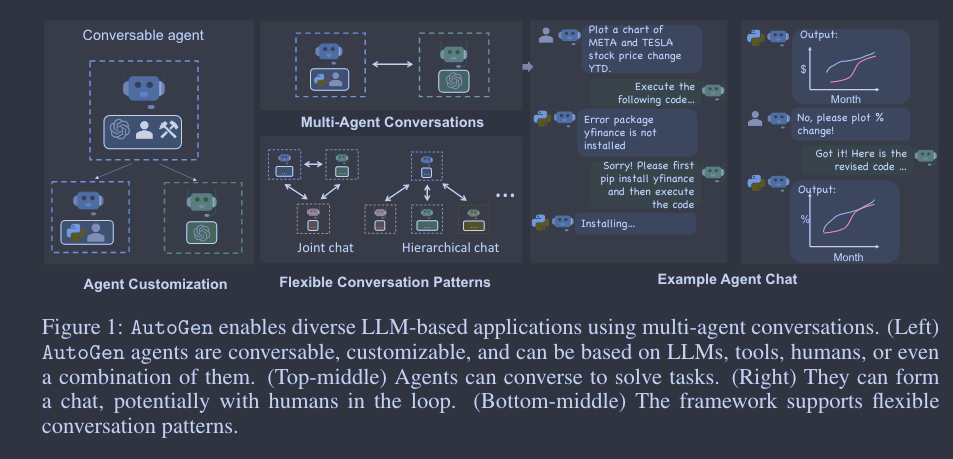
摘要 AutoGen 是一个开源框架,允许开发人员通过多个代理构建 LLM 应用程序,这些代理可以相互对话以完成任务。AutoGen 代理是可定制的、可对话的,并能以各种模式运行,这些模式采用 LLM、人类输入和工具的组合。使用 AutoGen,开发人员还可以灵活定义代理交互行为。自然语言和计算机代码都可用于为不同应用编程灵活的对话模式。AutoG…
前几天我分享了一篇跟Agent研究有关的文章,文章最后说过我还有一篇想要分享的,今天我就给大家带来了,它就是 “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation”。 我们知道,LLM不仅能够生成文本,还能进行复杂的任务和计算。然而,尽管这些模型具有巨大的…
好久没更新论文的分享了,今天来给大家分享一篇最近阅读的个人感觉非常有价值的一篇:MEMGPT: TOWARDS LLMS AS OPERATING SYSTEMS。我们都知道无论是ChatGPT、LLaMA、Claude等等大模型,虽然支持结合上下文进行对话,但这个对话长度实际是受限的,尤其是如果想进行长文档处理的时候就更头疼了,那么对于大模型这种…