不久前,NeurIPS 官方公布了 2023 年度的获奖论文,其中时间检验奖颁发给了10年前的论文「Distributed Representations of Words and Phrases and their Compositionality」。这篇论文可以看做是Word2Vec的第二篇论文。第一篇是「Efficient Estimation of Word Representations in Vector Space」,但是这第二篇论文提出的改进算法使得Word2Vec广泛应用起来的。我想各位AI从业者尤其是NLP领域的从业者对此已经非常熟悉了,作为一个刚入门的小白今天就简单回顾一下Word2Vec算法的知识。这篇文章因为有一些数学公式,因此排版看着回有点难受,介意的话可以点击原文去掘金看哦。
Efficient Estimation of Word Representations in Vector Space
先从论文1开始讲起,这篇论文提出了两个重要的模型:CBOW(continuous bag-of-words) 模型和skip-gram模型。这两个模型的算法是正好完全相反的,理解其中一个,另一个也很容易就能明白。
CBOW模型
先看第一个CBOW模型。首先随便定义一句话,比如:
"I have a pen and you have an apple"
CBOW模型是给定上下文,预测目标词的神经网络。简单的说,就是给定某个单词前后的一些单词来预测这个单词。对于上面这句话,如果上下文只考虑两个单词的话,上下文和目标词可以表示成下面这个表格:
| contexts | target |
|---|---|
| i, a | have |
| have, pen | a |
| a, and | pen |
| pen, you | and |
| and, have | you |
| you, an | have |
| have, apple | an |
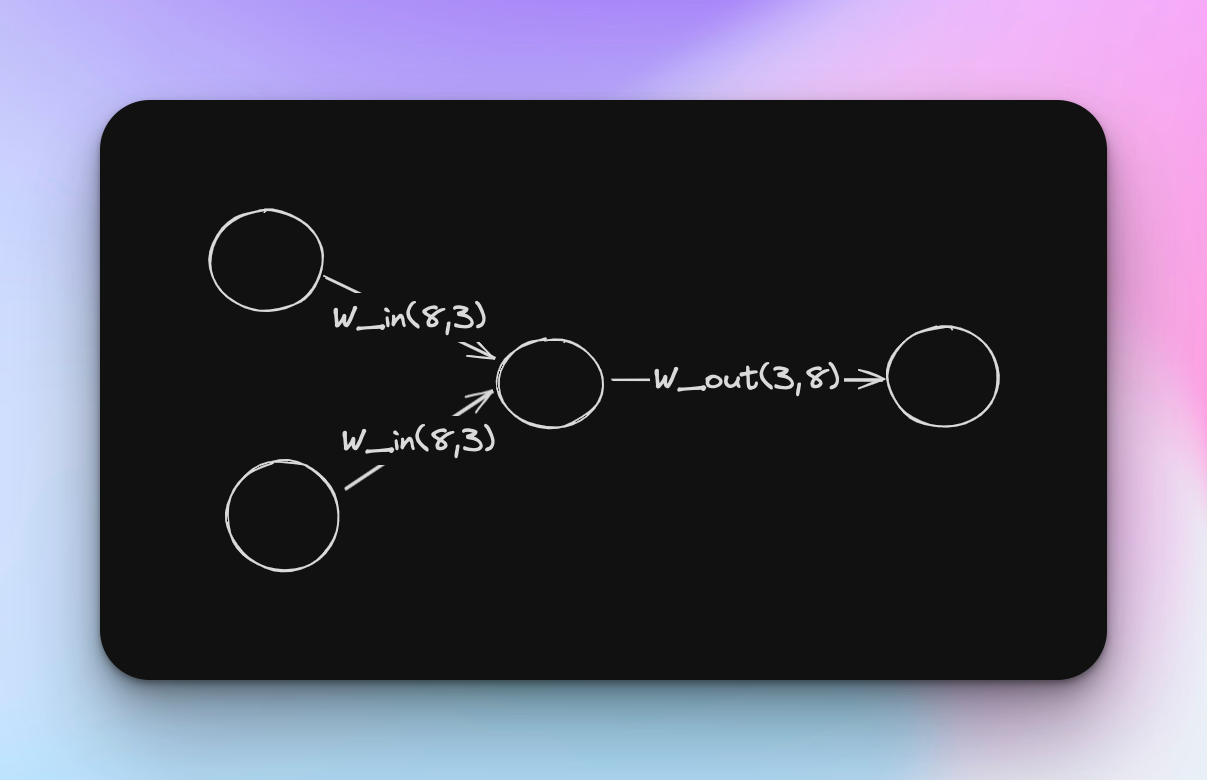
那么针对这种情况,CBOW模型的输入层有两个,你可以理解成左边的单词和右边的单词。当然如果上下文考虑N个单词的话, 输入层就是N个了。那么对于隐藏层,我们就先随便定义一个3,那么对于这个案例,输入层的权重W的形状是怎样的呢?
我们知道,神经网络的计算本质上都是数学计算,单词自然不能直接计算,因此一般都是转换成one-hot向量,所谓one-hot向量,就是有一个元素为1,其他元素均为0的向量。在这个例子中,我们句子的长度是9,但其‘have’这个单词重复了,语料库的大小其实是8,那么我们可以把这句话从左到右标记成如下所示的样子:
 然后对每个单词进行转换,比如’have’这个单词的one-hot向量为: (0, 1, 0, 0, 0, 0, 0, 0)。那么我们可以构建contexts和target分别为(7, 2, 8) 和 (7, 8)的矩阵。接下来就使用常见的深度学习的方式搭建神经网络即可。
然后对每个单词进行转换,比如’have’这个单词的one-hot向量为: (0, 1, 0, 0, 0, 0, 0, 0)。那么我们可以构建contexts和target分别为(7, 2, 8) 和 (7, 8)的矩阵。接下来就使用常见的深度学习的方式搭建神经网络即可。
我们这个示例的语料库就是一句话,网络也是非常简单的,仅仅作为示例。
从数学的角度来分析CBOW模型可能更简单,我们先确认几个概念:
- 先验概率:事件 A 发生的概率记作 P(A)
- 联合概率:事件 A 和事件 B 同时发生的概率记为 P(A, B)
- 后验概率:在给定事件 B 时事件 A 发生的概率,记为 P (A | B )
在CBOW模型中,总的思想是给定上下文,输出目标词的概率,假设我们现在有一连串的单词: $$ w_1,w_2,w_3…w_{t-1},w_t,w_{t+1}…w_{T},w_{T+1}… $$ 那么给定上下文 $w_{t-1}$ 和 $w_{t+1}$ 时(我们还是假定窗口为1哈)目标词为 $w_t$的概率记作: $$ P(w_t | w_{t-1}, w_{t+1}) $$ 我们上文使用的损失函数是交叉熵误差函数: $$ L = -\sum_k t_k \log y_k $$ $t_k$ 是对应于第 k 个类别的监督标签。log 是以 e 为底的对数。监督标签以 one-hot 向量的形式表示。在这里,$w_t$ 发生是正确的事件,因此,它对应的位置的one-hot是1,其他位置是0。那么上述公式可以推导成: $$ L = -log P(w_t | w_{t-1}, w_{t+1}) $$ 这也称作负对数似然 (negative log likelihood)。扩展到整个语料库的话,就是: $$ L = – \frac {1}{T} \sum_{t=1}^T log P(w_t | w_{t-1}, w_{t+1}) $$ CBOW模型的学习任务就是求解这个L最小,这样我们就可以得到一个文本转向量的模型。
skip-gram模型
了解了CBOW模型后再看skip-gram模型会很轻松就能看懂,表格都没必要画出来,因为它们俩正好相反,CBOW 模型从上下文的多个单词预测中间的单词(目标词),而 skip-gram 模型则从中间的单词(目标词)预测周围的多个单词(上下文),咱们把上面的神经网络反过来就差不多变成了skip-gram了。
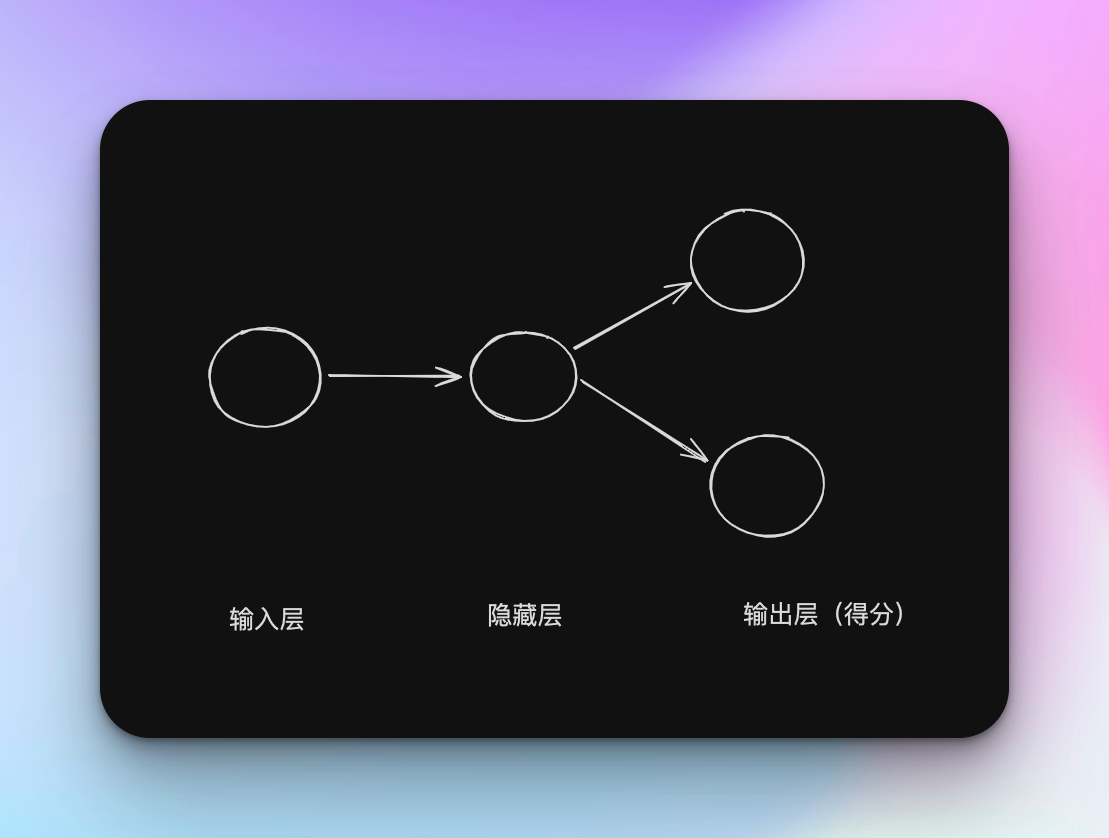
输入层就只有target了,而输出层则变成了contexts,比如我这里窗口还是1,那么就是2个。
那么对于数学公式的表示同样只需要稍微变一下位置,但要注意,这里是假定上下文的单词之间是相互独立,即没有相关性的。 $$ P (w_{t-1},w_{t+2} | w_t) = P (w_{t-1} | w_t) P(w_{t+1} | w_t) $$
代入损失函数: $$ L = -\log P(w_{t-1}, w_{t+1} | w_t) \ = -\log P(w_{t-1}|w_t)P(w_{t+1}|w_t) \ = -(\log P(w_{t-1}|w_t) + \log P(w_{t+1}|w_t)) $$ 对于整个语料库就是: $$ L = -\frac{1}{T} \sum_{t=1}^T (\log P(w_{t-1}|w_t) + \log P(w_{t+1}|w_t)) $$ 那么将它和上面的CBOW最终的公式对比可以很明显看出,skip-gram模型预测次数和上下文单词数量是一样多的,但CBOW只需要求目标词的损失即可。从单词的分布准确度来看,大多数情况下,skip-gram模型表现更好, 但显然计算成本要比CBOW高。
Distributed Representations of Words and Phrases and their Compositionality
负采样
那接下来就是第二篇论文,也就是这次的获奖论文了。
上面的模型虽好,但随着语料库的增加,计算量也会随之增大。对于上面的例子,语料库只有8个单词,那么如果对于词汇量是100万的语料库呢?假设中间神经元个数为100,那么在CBOW模型中,权重W的规模就是(100万,100),那么矩阵乘积需要的时间以及内存占用就很大了。此外我们上文说的Softmax函数的计算量也是跟词汇量成正比。因此我们需要一个方法能够减少我们的计算量,它就是负采样(Negative Sampling)。
这个方法的重点在于将多分类问题转为二分类的问题,我们原本的问题可能是,对于上下文是“have”,“apple”,目标词是什么?换成二分类可以理解为:对于上下文是“have”,“apple”,中间词是“an”吗?这样原本的多分类问题就变成了一个是或否的二分类问题。
说到二分类,自然就会想到sigmoid函数这个老朋友了,损失函数依然用交叉熵误差。sigmoid函数的公式如下: $$ y = \frac{1}{1+e^{-x}}
$$ 损失函数: $$ L = -(tlogy + (1-t)log(1-y)) $$ y 是输出,t 是正确标签0 or 1。因此t = 1是,L = -logy, t=0时, L = -log(1-y)。
对于这个函数,最有意思的自然就是求L对x的偏导了 $$ \frac{\partial L }{\partial x} = \frac{\partial L}{\partial y} \frac{\partial y}{\partial x} = – \left( \frac{t}{y} – \frac{1-t}{1-y} \right) y(1-y) = y – t $$
虽然 L 看着很复杂,但最终的偏导结果很简单。这意味着,当 y 和 t 越接近,误差就越小,模型参数更新的力度就越小。
对于CBOW模型,原本最后输出是通过Softmax函数得到的多分类结果,现在我们只将隐藏层输出的h和输出层权重W_out中的目标单词对应的单词向量做内积,然后再输入到sigmoid with loss计算损失。至此咱们就成功把多分类转成二分类问题啦。
BUT,这一节的标题叫做Negative Sampling,并不是什么多分类转二分类,我们目前干的事相当于知道正确答案去解正确答案,我们还要做的就是标题描述的:负采样。比如上文的“have”,“apple”的例子,如果目标词是“an”,sigmoid的结果应当是无限接近于1的,但如果换成什么“abandon”,那肯定希望它是输出接近于0。怎么处理呢?总不能把所有剩余的错误答案都放进来训练,可我们的出发点是减少计算量,全放进来计算就又回到过去了,所以我们应该只使用部分的负例。
在论文中,负采样方法抽取负例(即非目标单词的样本)的方式与噪声对比估计(Noise Contrastive Estimation, NCE)有所不同。负采样只使用样本,而不需要噪声分布的数值概率,这与NCE的要求不同。NCE旨在近似最大化softmax的对数概率,但对于负采样,这一属性并不重要。而且文中发现单词分布U(w) 的0.75次方在包括语言建模在内的所有尝试的任务上都显著优于单词分布和均匀分布,无论是对于NCE还是负采样。使用这种方式,低频单词的概率将稍微变高,使得模型不仅关注于频繁出现的单词,而且还考虑到了稀有单词,从而可以更全面地学习单词之间的关系(0.75 这个值并没有什么理论依据,也可以设置成 0.75 以外的值。)
此外,论文还用到了另一个方法:频繁单词的二次抽样。也是一种用来平衡训练数据中罕见词和常见词影响的方法。这种方法的基本思想是,在训练过程中,对于出现频率高的词进行抽样,以减少它们在训练数据中的占比。具体来说,每个单词 $w_i$ 在训练集中被丢弃的概率由以下公式计算: $$ P(w_i) = 1 – \sqrt{\frac{t}{f(w_i)}} $$
其中 $f(w_i)$ 是单词 $w_i$ 在数据集中的频率,而 t 是一个预先选择的阈值。这种方法的目的是降低高频词在训练过程中的影响,因为这些词通常提供的信息量较少。例如,单词“the”在大多数句子中频繁出现,但与其他词的共现并不提供太多有用的语义信息。
通过实施这种二次抽样方法,模型训练过程中对罕见词的关注度提高,有助于学习到更丰富和准确的词向量表示。这种方法特别适用于大型语料库,可以显著提高训练效率并改善词向量的质量。
Learning Phrases
除了负采样的方式,这篇论文还介绍了另一个提升自然语言学习的方法。核心是扩展Skip-gram模型,以支持短语的学习。这一扩展对于理解和表示自然语言非常重要,因为自然语言中的许多含义是通过短语而非单个单词来表达的。短语通常承载比单个词更丰富的信息和更复杂的语义。例如,“hot dog”或“New York”这样的短语含义不能简单从“hot”、“dog”、“New”和“York”这些单词的含义直接推导出来。此外通过理解和表示短语,模型可以更准确地处理自然语言,尤其是在涉及特定上下文或特定领域(如医学、法律等)的应用中。
如何学习短语呢,我们可以通过统计分析词对(bigrams)的共现频率来评估它们是否应该被视为一个短语,公式如下: $$ score(w_i, w_j) = \frac{count(w_i w_j) – \delta}{count(w_i) \times count(w_j)}. $$ 它可以用于评估两个单词 $w_i$ 和 $w_j$ 是否应当组成一个短语。这里:
- $count(w_i w_j)$表示两个单词$w_i$ 和 $w_j$ 作为连续对出现的次数。
- $\delta$是一个折扣系数,用于调整公式中的频率乘积,以防止形成由非常不频繁的单词组成的短语。
- $count(w_i)$和$count(w_j)$ 分别是单词 $w_i$和 $w_j$ 在整个数据集中出现的次数。 通过设定一个阈值,可以选择得分超过此阈值的词对作为短语。这种方法使得可以从大量文本中自动识别出有意义的短语,可以一定程度上避免只分析单个单词而导致一些语义被破坏的问题。
总结
总的来说,读这些经典的而且又是里程碑式的论文真的很令人收益良多,想起之前学习分布式系统的时候阅读谷歌的三驾马车也是这个感觉,国外的有些课程会推荐这些论文作为阅读材料,比如斯坦福的cs224n,MIT的6.824这些有名气的课程,本人学习能力有限,但幸好有这些课程和论文帮助我继续学习,虽然都挺难啃的,但啃下来绝对舒爽,也很推荐大家偶尔刷一刷这些公开课。
PS:最近偷懒好久没更新了,希望后面能继续坚持至少一周一更哈哈。