原书地址:https://udlbook.github.io/udlbook/ 人工智能(AI)旨在打造模仿智能行为的系统。它覆盖了众多方法,涵盖了基于逻辑、搜索和概率推理的技术。机器学习是 AI 的一个分支,它通过对观测数据进行数学模型拟合来学习决策制定。这个领域近年来迅猛发展,现在几乎(虽不完全准确)与 AI 同义。 深度神经网络是一类机器学习…
不久前,NeurIPS 官方公布了 2023 年度的获奖论文,其中时间检验奖颁发给了10年前的论文「Distributed Representations of Words and Phrases and their Compositionality」。这篇论文可以看做是Word2Vec的第二篇论文。第一篇是「Efficient Estimatio…
最近因为有事没事就看看论文,虽然现在有GPT的帮助能提升不少效率,但其实对于一个科研小白而言还是非常吃力的。今天分享两个阅读论文的方式,一个是2007年就发表过的S. Keshav的How to Read a Paper,另一个是沈向洋博士提出的论文十问。相信已经有很多做科研的同学们都已经对看论文很熟练了,但对于刚开始入门的同学而言,这两个论文阅读…
长期潜水在各个LLM技术群的小透明今天看到了智谱AI和清华团队又整了一篇有意思的论文,叫做Black-Box Prompt Optimization: Aligning Large Language Models without Model Training 主要是解决大模型的"对齐问题"。 啥叫对齐问题呢?指的是确保人工智能(…
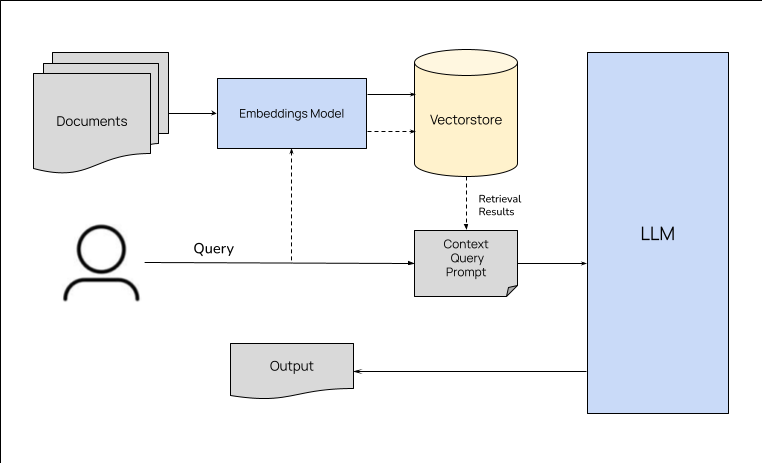
今天又看了一篇好玩的关于RAG玩法的论文,叫做 SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION 。 核心思想很有意思,让LLM自己对自己说的话反思反思(脑海里不由得就想起前不久某知名主播说的让我们反思的话了)。接下来我就大致介绍一下这个方法…
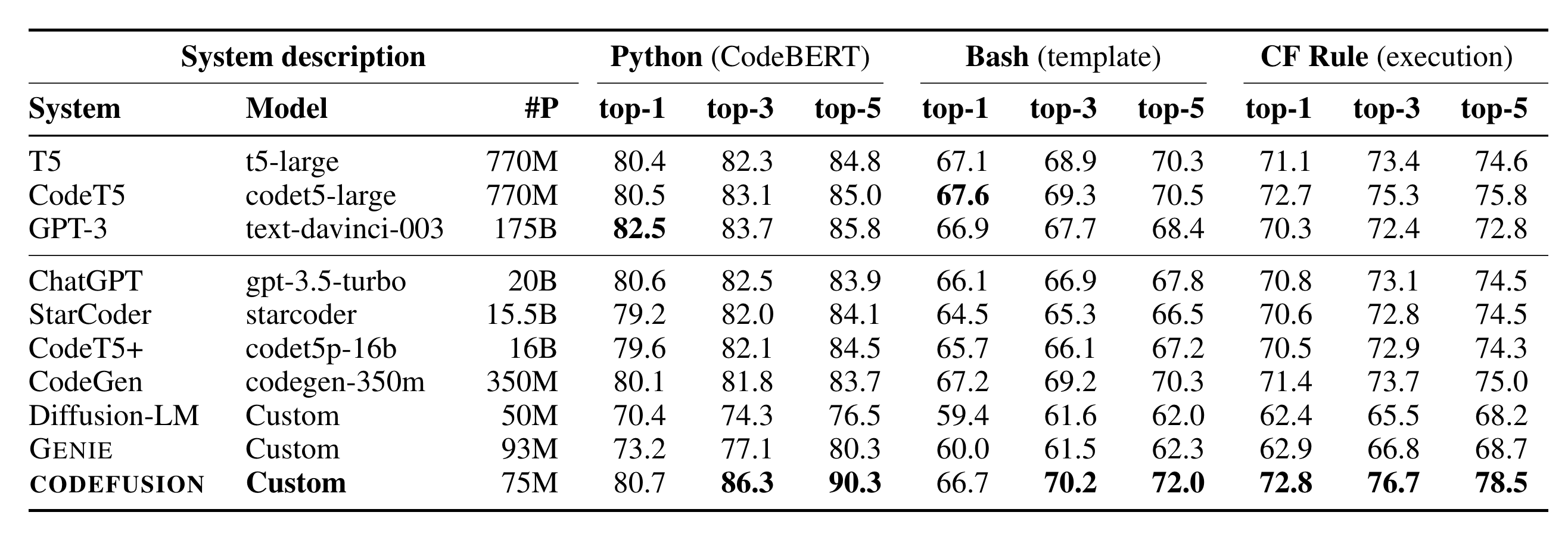
微软在10.26日发表了一篇论文CODEFUSION: A Pre-trained Diffusion Model for Code Generation,主要内容是提出了一个叫做CodeFusion的模型,它是一个基于扩散模型的从自然语言到代码生成模型,相对于论文提到的这个模型,更劲爆的是论文中的一张表格:看到图中的System descript…