终于到序列模型课程最后一周的内容了,本篇博客依然是基于Andrew Ng的深度学习专项课程的序列模型来编写的,本篇内容不会很多,主要就是Transformer网络相关的知识点,Transformer网络是一种基于注意力机制的神经网络架构,被广泛应用于自然语言处理领域,尤其是机器翻译任务中。本文将详细介绍Transformer网络的关键概念和工作原理。废话不多说,现在开始吧。
Transformer 网络介绍
我们前面讲解过在序列模型中常用的技术包括RNN、GRU和LSTM,这些模型虽然解决了一些问题,包括梯度消失、长距离依赖等,但模型的复杂度也随之增加了不少。它们都是顺序模型,会将输入一个词或一个标记地顺序处理。显然这样的处理性能是比较弱的。
Transformer架构创新性地将注意力机制和CNN相结合,允许我们对整个序列进行并行计算,可以一次处理整个句子,而不是从左到右逐词处理。它的核心理念主要是自注意力(Self Attention)和多头注意力(Multi-Head Attention) 这两点。 简单来说,如果我们有一个包含5个词的句子,自注意的目标是并行地为这五个词计算出五个标识。而多头注意力就是对自注意力过程进行循环,从而得到这些表示的多个版本,这些表示是非常丰富的,可以用于机器翻译或其他NLP任务。
Self-Attention
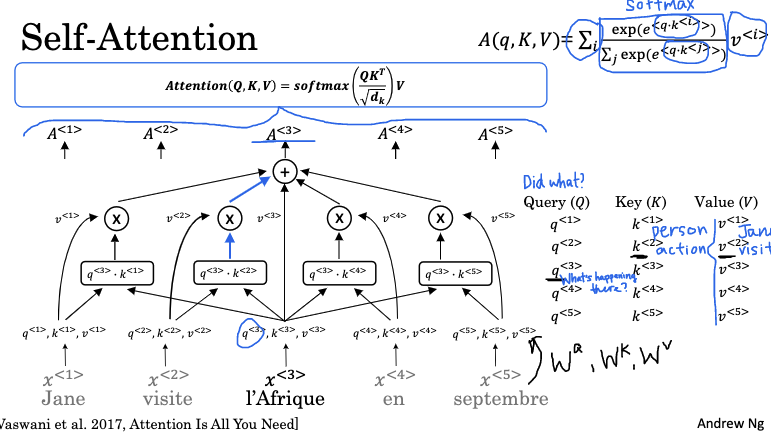
自注意力(Self-Attention)机制是Transformer网络的核心组件。它可以对序列进行并行计算,为序列中的每个词汇生成一个注意力向量,表示其在特定上下文中的含义。
自注意力机制可以帮助我们理解每个单词在特定上下文中的含义。比如,"Africa"这个词,在不同的上下文中可能代表历史兴趣的地点,或者假期的目的地,或者世界第二大洲。自注意力机制会根据周围的单词来确定在此句子中我们谈论的"非洲"的最合适的表示方式。

自注意力机制为序列中每个词汇计算出一个Query向量、Key向量和Value向量。其具体计算步骤如下:
- 首先,我们将每个单词与查询、键和值对应起来。这些对由学习到的矩阵和该单词的嵌入向量相乘得到。
- 查询可以看作是对单词的一个问题,例如,对"Africa"的问题可能是"那里发生了什么?"。
- 我们计算查询和每个键的内积,来确定其他单词对查询问题的回答的质量。
- 我们对所有内积结果进行softmax运算,这样可以获得每个单词的注意力值。
- 最后,我们将得到的softmax值与相应单词的值向量相乘,并将结果相加,得到的就是我们需要的自注意力表示。
自注意力机制的优点在于可以根据整个序列的上下文来获得每个词汇的表示,而非仅依赖于临近词汇。同时,其并行计算性质也大大提升了模型的训练和推理效率。
我们对序列中的所有单词执行上述计算过程,以获取相应的自注意力表示。最后,所有这些计算可以由Attention(Q, K, V)进行概括,其中Q,K,V是所有查询、键和值的矩阵。值得注意的是,这里Query、Key、Value矩阵的计算都使用了不同的权重矩阵,这使得自注意力机制可以学习输入序列的不同表示。
自注意力机制的结果是每个词的表示都更为丰富和细致,因为它考虑了每个词左右的上下文。
Multi-Head Attention
Multi-Head Attention 机制对自注意力机制进行拓展,允许模型联合学习序列的不同表示子空间。
多头注意力将输入序列重复进行自注意力计算n次,每次使用不同的权重矩阵,得到n个注意力向量序列。然后将这n个序列拼接并线性转换,得到最终的序列表示,即:
$$ MultiHead(Q, K, V) = concat(head_1, …, head_n)W_o $$
$$ where \ head_i = Attention(W_i^QQ, W_i^KK, W_i^VV) $$ 每次计算一个序列的自注意力被称为一个"头",因此,“多头注意力"就是多次进行自注意力计算。每个"头"可能对应着不同的问题,例如第一个"头"可能关注"发生了什么”,第二个"头"可能关注"何时发生",第三个"头"可能关注"与谁有关"等等。
多头注意力的计算过程与自注意力基本一致,但是使用了不同的权重矩阵(,并且将所有的注意力向量(一般情况下是8个)进行拼接,再乘以一个权重矩阵,最后得到的结果就是多头注意力的输出。在实际计算中,由于不同"头"的计算互不影响,可以同时计算所有的"头",即并行计算,以提高计算效率。
总的来说,多头注意力机制可以为每个单词学习到更丰富、更好的表示,每个"头"都能从不同的角度去理解序列中的每个单词。
Transformer 网络
在Transformer网络中,Encoder和Decoder均由多头注意力层和全连接前馈网络组成,网络的高层结构如下:
- Encoder由N个编码器块(Encoder Block)串联组成,每个编码器块包含:
- 一个多头注意力(Multi-Head Attention)层
- 一个前馈全连接神经网络(Feed Forward Neural Network)
- Decoder也由N个解码器块(Decoder Block)串联组成,每个解码器块包含:
- 一个多头注意力层
- 一个对Encoder输出的多头注意力层
- 一个前馈全连接神经网络

我们以一个法语翻译成英语的例子来讲解这个过程:
- 首先,输入句子的嵌入会被传递到编码器块,该块具有多头注意力机制。将嵌入和权重矩阵计算出的Q,K和V值输入到这个模块,然后生成一个可以传递到前馈神经网络的矩阵,用于确定句子中有趣的特性。在Transformer的论文中,这个编码块会被重复N次,一般N的值为6。
- 然后,编码器的输出会被输入到解码器块。解码器的任务是输出英文翻译。解码器块的每一步都会输入已经生成的翻译的前几个单词。当我们刚开始时,唯一知道的是翻译会以一个开始句子的标记开始。这个标记被输入到多头注意力块,并用于计算这个多头注意力块的Q,K和V。这个块的输出会用于生成下一个多头注意力块的Q矩阵,而编码器的输出会用于生成K和V。
- 解码器块的输出被输入到前馈神经网络,该网络的任务是预测句子中的下一个单词。 除了主要的编码器和解码器块,Transformer Network还有一些额外的特性:
- 位置编码:对输入进行位置编码,以便在翻译中考虑单词在句子中的位置。使用一组正弦和余弦方程来实现。
- 残差连接:除了将位置编码添加到嵌入中,还通过残差连接将它们传递到网络中。这与之前在ResNet中看到的残差连接类似,其目的是在整个架构中传递位置信息。
- Adenome层:Adenome层类似于BatchNorm层,其目的是传递位置信息。
- 遮掩多头注意力:这只在训练过程中重要,它模拟网络在预测时的行为,看看给定正确的前半部分翻译,神经网络是否能准确地预测序列中的下一个单词。
总结
Transformer网络通过引入自注意力和多头注意力等机制,实现了序列建模的质的飞跃,在机器翻译、文本摘要、问答系统等任务上都取得了极大的成功。研究表明,其并行计算结构也使Transformer网络相比RNN等模型具有显著的计算效率优势,如今百家争鸣的大模型底层其实也离不开它的身影,理解它对于学习那些大语言模型是非常有帮助的。