循环神经网络(Recurrent Neural Network, RNN)是一种能够处理序列数据的神经网络,在自然语言处理、语音识别、手写识别等领域发挥着重要作用。相比普通的前馈神经网络,RNN可以捕捉时间序列数据中的时序信息和长距离依赖关系。本篇博客将详细介绍RNN的工作原理、常见模型如门控循环单元(GRU)、长短期记忆(LSTM)以及如何应用于具体问题中。
同样的,本篇博客也是来自于Andrew Ng教授的Deep Learning 专项课程,由于我本人对NLP更感兴趣,因此我这里跳过了CNN这门课先写关于最后一门序列模型这么课的博客,后续有空再整理CNN的内容。
什么是序列模型?
序列模型是一种特殊的神经网络模型,适用于输入和/或输出是序列的问题,例如语音识别、机器翻译和时间序列分析。传统的神经网络,如前馈神经网络或卷积神经网络,在处理这类序列数据时可能遇到挑战,因为它们不能很好地捕捉时间序列中的时间依赖性。
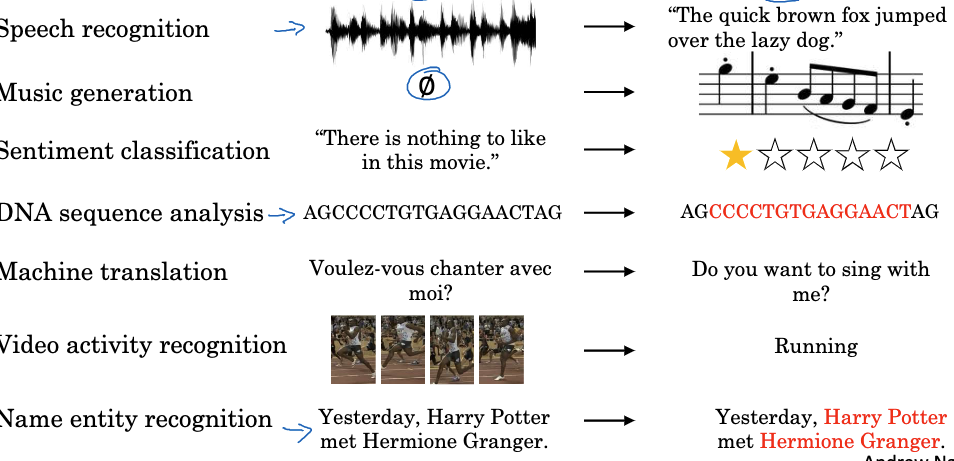
使用序列模型的主要原因是:
- 它可以捕捉时间序列中的依赖关系。
- 它可以处理变长的输入和输出。
- 它广泛用于NLP、语音识别、视频处理等应用中。
数学符号解释
在处理序列数据时,我们经常会遇到一个核心问题:如何有效地在神经网络中表示和处理时间或序列的概念。循环神经网络(RNN)为我们提供了一种有效的解决方案。为了更好地理解RNN的运作原理,我们需要先了解其背后的数学符号和基本概念。
在RNN中,我们通常会处理序列数据。考虑一个序列数据 $X = (x^{(1)},x^{(2)},…, x^{(T_x)})$,其中每一个$x^{(t)}$代表序列中的一个元素或时间步。
- $x^{(t)}$: 在时间步t的输入。
- $y^{(t)}$: 在时间步t的输出。
- $a^{(t)}$: 在时间步t的激活值或隐藏状态。
- W, U 和 V: 权重矩阵。
- 词汇表:为了表示句子中的词,首先需要创建一个词汇表,也被称为字典,这就是你将在表示中使用的词的列表。每个词都用一个one-hot向量来表示,也就是说,如果词汇表中有10000个词,那么每个词都会被表示为一个10000维的向量,其中只有一个位置是1,其余位置都是0。这个位置就是这个词在词汇表中的位置。
- 未知词汇:如果遇到不在词汇表中的词,就创建一个新的标记,通常用UNK表示,表示这是一个未知的词。
举个例子,假设有一个句子X:
Harry Potter and Hermione Granger invented a new spell.
我们需要让模型自动识别出句子中的人名。这种问题称为命名实体识别(Named-entity recognition)。给定输入x(Harry, Potter等),我们希望模型能产生一个输出y,每一个输入词对应一个输出。目标输出y告诉你每一个输入词是否是人名的一部分,用$y^{(t)}$表示。在我们使用的符号中,$T_x$是输入序列的长度,$T_y$是输出序列的长度。
RNN模型
在讨论RNN之前,我们首先思考一个问题,为什么不使用之前学习过的标准网络呢?
 那是因为对于序列模型,序列长度往往很长,而且输入和输出的长度不一定相同,比如语言翻译问题,两种语言的同一句话可能使用的单词数量是不一样的。此外,对于不同位置学习到的特征,它们其实没有共享,但对于句子而言,每个单词之间可能是存在联系的,比如单复数的使用,时态的使用等等。
那是因为对于序列模型,序列长度往往很长,而且输入和输出的长度不一定相同,比如语言翻译问题,两种语言的同一句话可能使用的单词数量是不一样的。此外,对于不同位置学习到的特征,它们其实没有共享,但对于句子而言,每个单词之间可能是存在联系的,比如单复数的使用,时态的使用等等。
而循环神经网络(RNN)是为处理时间序列数据而设计的。与传统的前馈神经网络相比,RNN可以记住其先前的输入,这使其特别适用于处理序列数据。前馈神经网络在处理序列数据时,无法捕捉时间序列中的时序信息和长距离依赖关系。
基本结构
在最基本的层面上,RNN的一个核心组件是其隐藏状态,它能够在时间步之间传递信息。每当网络接收到新的输入时,它都会更新其隐藏状态,并产生一个输出。这使RNN能够保持关于先前输入的记忆,并在必要时使用这些信息。
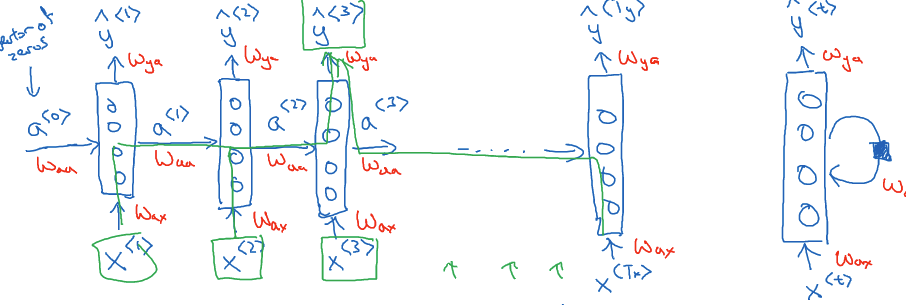
前向传播
RNN的前向传播过程定义了如何根据给定输入和当前隐藏状态来计算新的隐藏状态和输出。其公式如下:
隐藏状态的更新: $$ a^{(t)} = g(W_{aa}a^{(t-1)} + W_{ax}x^{(t)} + b_a ) $$ 其中,$W_{aa}$和$W_{ax}$是权重矩阵,用于更新隐藏状态,$a^{(t-1)}$是上一个时间步的隐藏状态,$x^{(t)}$是当前时间步的输入。其中激活函数g可以使用tanh或ReLU。
计算输出: $$ y_{(t)} = g(W_{ya}a^{t} + b_y) $$

后向传播
对于RNN,后向传播(通常称为通过时间的反向传播)是一个稍微复杂的过程。它涉及计算损失函数对权重的梯度,并相应地更新权重。
对于给定的时间步t,梯度可以用以下方式计算,$\hat{y}^{(t)}$是真实的目标输出: $$ \frac{\partial L}{\partial y^{(t)}} = y^{(t)} – \hat{y}^{(t)} $$
考虑到隐藏状态在多个时间步之间传递,计算其梯度需要考虑当前时间步和之前所有时间步。根据链式法则,可以计算出损失函数对权重的梯度。在这个反向传播过程中,最重要的递归计算是从右向左进行的,这就是为什么这个算法有一个很酷的全名:通过时间反向传播(Backpropagation Through Time)。这个计算太复杂就不仔细讲了。
总的来说,RNN的前向传播和后向传播为我们提供了一种在时间步之间传递和使用信息的机制。这使RNN能够处理各种复杂的序列任务,从语言建模到时间序列预测。
RNN的不同类型
在处理序列数据时,我们经常遇到各种任务,需要不同的输入输出结构。RNN的强大之处在于它的结构可以根据特定任务的需求进行调整。结合第一节的几个序列模型的示例,我们可以得到几种不同的RNN架构。 1. One-to-One 这是最基本的结构,给定每一个输入都对应一个输出。 2. One-to-Many 在这种结构中,单一输入产生一个序列作为输出,比如音乐生成,我们可能输入一个简单的音符,输出一个音乐片段,公式化地说,给定一个输入x,模型将产生一个输出序列$y^{(1)},y^{(2)}… y^{(T_y)}$ 3. Many-to-One 在这种模型中,模型接收一系列的输入,并生成一个单一输出,最典型的应用就是情感分析,输入一个句子或评论,模型输出一个情感标签(如正面、负面或中立。) 公式化的说,就是给定输入$x^{(1)},x^{(2)}… x^{(T_x)}$,输出一个y。 4. Many-to-Many 在这种情况下,输入和输出的长度可以一样也可以不一样,一样的话就比如命名实体识别,不一样的话就比如机器翻译,不同语言输出的句子长度就可能是不一样的。
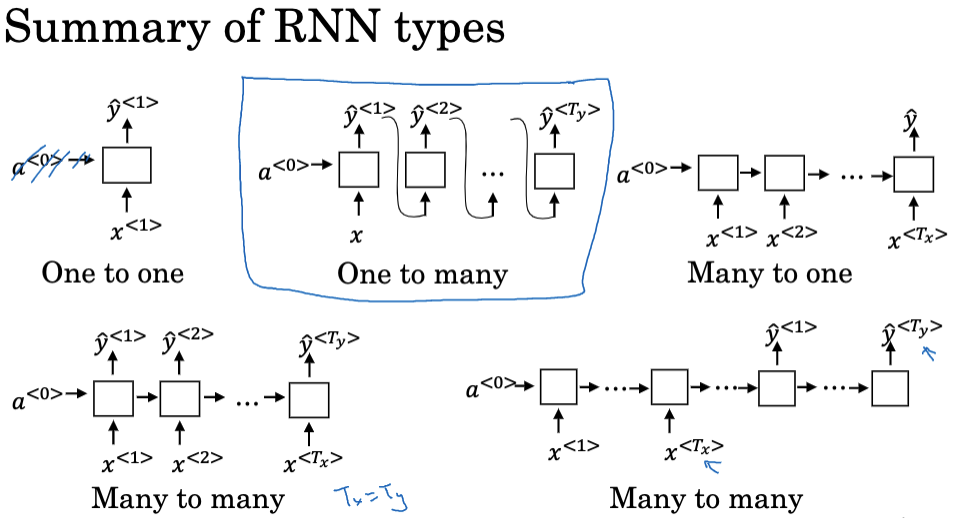
因此总的来说,RNN的灵活性允许它适应各种序列处理任务。理解不同的RNN结构及其应用是设计有效序列处理系统的关键。不论是为了生成文本,分类句子,还是翻译语言,RNN都提供了强大的框架,可以根据任务需求进行调整。
语言模型与序列生成
语言模型是NLP领域中的核心应用,它允许机器学习和理解人类语言的结构。它旨在预测给定前面的单词后,下一个单词是什么。形式上,它评估一个句子的概率或者给定前面的单词,评估下一个单词的条件概率。 对于句子 $w_1, w_2, …, w_T$,语言模型尝试优化以下概率: $$ P(w_1, w_2, …, w_T) = \prod_{t=1}^{T}P(w_t | w_1, w_2, …, w_{t-1}) $$
这意味着,模型试图找到最佳的单词序列,使整个句子的概率最大化。由于RNN的“记忆”能力,它可以存储前面的单词信息,并用这些信息来预测下一个单词。在每个时间步,RNN都会根据其当前的隐藏状态(它编码了先前的单词)和当前单词来更新其状态,并预测下一个单词。
一旦训练了RNN语言模型,我们可以使用它来生成新的文本序列。这通常通过以下步骤完成:
- 开始于某个初始词或序列。
- 使用模型预测下一个最可能的单词。
- 将该单词添加到序列中。
- 重复此过程,直到生成所需长度的序列或遇到特定的结束标记(<EOS>)。
在我们的日常生活中,从音乐、故事到艺术作品,都涉及到一种创造性的生成过程。同样,RNN也可以生成具有某种创造性的序列样本。
一旦我们有了一个经过训练的模型,我们可以使用它来预测下一个最可能的输出。但是,仅选择最可能的输出可能导致生成的序列过于单调。相反,我们可以从模型输出的概率分布中随机选择下一个项,这样可以增加生成内容的多样性。如果模型在新闻文章上进行训练,那么它生成的文本可能看起来像新闻文本。如果它在莎士比亚的文本上进行训练,那么它生成的东西可能听起来像莎士比亚可能写的东西。
RNN中的梯度消失
在之前的课程中我们已经学习过什么是深度学习中的梯度消失和梯度爆炸。先回归一下它们的基础概念:
- 梯度消失:当我们反向传播误差时,梯度可能会随着每一层变得越来越小,直到它几乎为零。这意味着网络的深层几乎不会更新其权重,导致训练过程停滞。
- 梯度爆炸:与梯度消失相反,梯度可能会随着每一层变得越来越大,导致权重更新过大。这可能使网络变得不稳定,甚至导致数值溢出。
RNN的特性是其反向传播过程中的连续乘法。当这些乘数小于1时,多次连续乘法可能导致值急剧下降(梯度消失)。相反,当这些乘数大于1时,连续乘法可能导致值急剧增加(梯度爆炸)。 但在RNN中,一般梯度消失问题相对来说会更为常见,因为要想得到梯度爆炸,这些因子需要持续大于1,但权重通常被初始化为较小的值(接近0),许多常用的激活函数(如tanh和sigmoid)都在其饱和区域有接近0的导数。这意味着当激活值进入这些区域时,梯度会迅速减小。对于tanh,它的输出范围是[-1,1],导数的最大值是0.25(在0处)。对于sigmoid,输出范围是[0,1],其导数的最大值也是0.25。当这些小于1的值被多次连续乘以自身时,它们迅速减小。
尤其在训练RNN时。了解这些问题的成因和如何解决它们,是训练稳定、高效的序列模型的关键。幸运的是,随着研究的深入,现在我们已经有了许多工具和策略来应对这些挑战。
GRU(Gated Recurrent Unit)
GRU,或门控循环单元,是RNN的一种变种,被设计出来特别用于解决梯度消失问题。它与传统的RNN不同,具有一种更复杂的内部结构,特别是它使用了“门”的概念来控制信息流。
GRU包含两个主要的门:重置门(Reset Gate)和更新门(Update Gate)。这些门控制状态信息的流动,允许模型“选择”在每个时间步保留或放弃多少旧信息。 ![[Pasted image 20230813154121.png]]
- 重置门r: 它决定了多少以前的信息将被“遗忘”或“重置”。
- 更新门u: 类似于LSTM中的遗忘和输入门的组合,决定了当前单元状态应该多少是新信息,多少是旧信息。
公式如下:
 GRU的设计有助于传递长距离的依赖关系,这是因为它的更新门允许之前的隐藏状态不受影响地传递下去,有助于减轻梯度消失问题。
GRU的设计有助于传递长距离的依赖关系,这是因为它的更新门允许之前的隐藏状态不受影响地传递下去,有助于减轻梯度消失问题。
LSTM(Long Short-Term Memory)
长短时记忆(LSTM,Long Short-Term Memory)网络是RNN的一种变体,它被设计来避免长期依赖的问题。简言之,LSTM能够存储和检索长期序列中的信息,这使其在众多涉及长序列的任务中都表现出色。
与传统RNN不同,LSTM设计得更加复杂。它有三个门:遗忘门、输入门和输出门,以及一个细胞状态。
- 遗忘门f: 决定哪些信息从细胞状态中遗忘或丢弃。
- 更新门u: 决定哪些新信息将存储在细胞状态中。
- 输出门: 基于细胞状态决定输出什么。
我们可以看看它与GRU的对比
 我们可以看到,GRU中的$1-\Gamma_U$ 其实就相当于LSTM中的$\Gamma_f$
![[Pasted image 20230813154830.png]]
LSTM和GRU在某种程度上是类似的,都是设计来解决梯度消失问题的。但是,LSTM具有三个门和一个明确的细胞状态,而GRU只有两个门。这种额外的复杂性使LSTM在某些任务上具有更好的表现,但同时也意味着它有更多的参数,需要更长的训练时间。
我们可以看到,GRU中的$1-\Gamma_U$ 其实就相当于LSTM中的$\Gamma_f$
![[Pasted image 20230813154830.png]]
LSTM和GRU在某种程度上是类似的,都是设计来解决梯度消失问题的。但是,LSTM具有三个门和一个明确的细胞状态,而GRU只有两个门。这种额外的复杂性使LSTM在某些任务上具有更好的表现,但同时也意味着它有更多的参数,需要更长的训练时间。
LSTM在长序列和复杂的任务中表现良好,尤其是当序列之间的依赖关系非常复杂或很长时。但由于其参数众多,需要大量的数据和计算资源进行训练。与GRU一样,在实际应用中,最好尝试多种模型并选择最适合的一个。而GRU尤其适合处理较短的序列和/或资源有限的情况(因为其参数较少)。
双向RNN
双向循环神经网络(Bidirectional Recurrent Neural Networks,简称BiRNN)是RNN的一个重要扩展,它能够捕获输入序列的前后信息。这种模型结构特别适合那些不仅依赖于先前的元素,而且还依赖于后续元素的任务。 举个例子:
He said, "Teddy bears are on sale!"
He said, "Teddy Roosevelt was a great Presideng!"
在这两个句子中,Teddy这个单词都出现了,但它代表了不同的意思,要想识别出它是泰迪熊还是人名,仅仅依靠前面的单词是无法判断的,还需要考虑后面的单词。
BiRNN的核心思想是对每一个时间步,都有两个方向的隐藏状态:一个从前到后(正向),一个从后到前(反向)。最终的输出是这两个方向上的隐藏状态的结合。
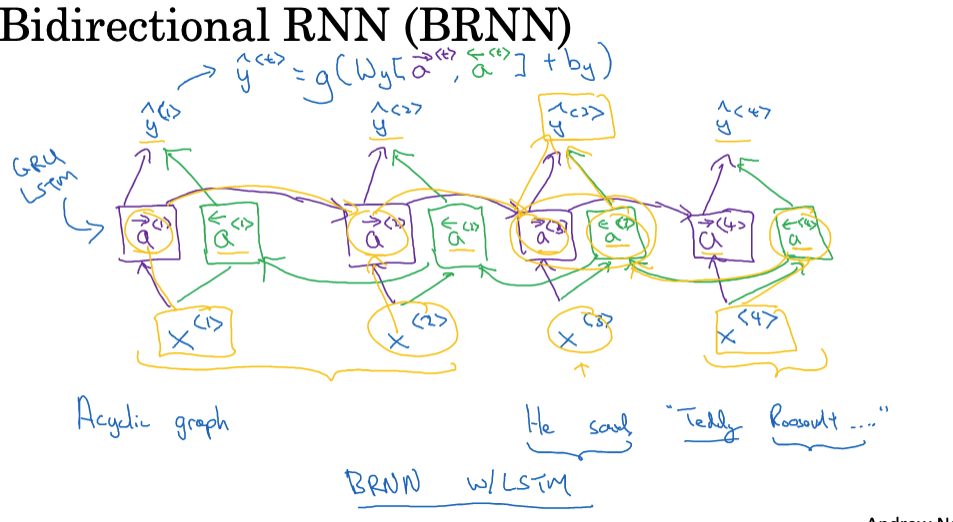
BiRNN在众多NLP任务中都已得到广泛应用,如机器翻译、情感分析和命名实体识别。当任务需要捕获序列的全局上下文时,BiRNN是一个很好的选择。
深度RNN
深度循环神经网络(Deep RNNs)参考了深度学习中深度前馈神经网络的思想,即在模型中堆叠多个隐层,以提高模型的表现力。这种策略目的是捕获数据中更高层次和更复杂的模式。
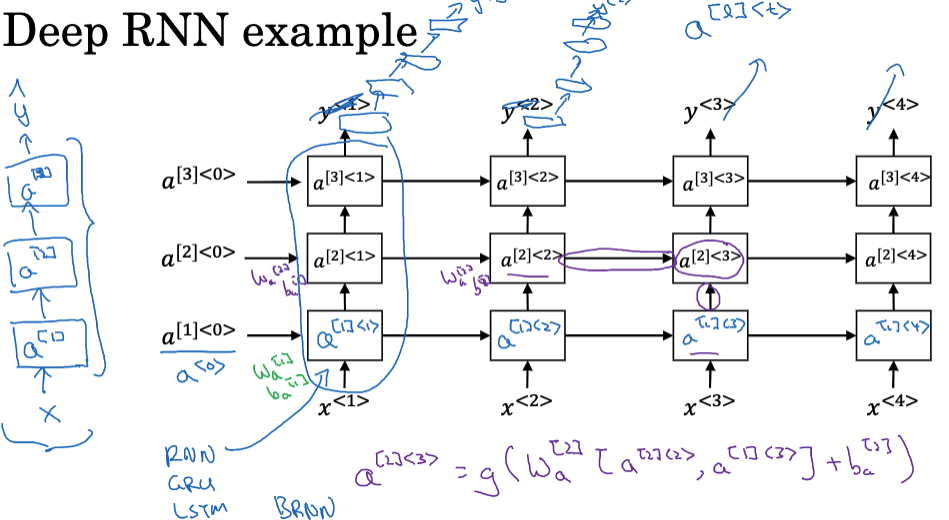 深度RNN是由多个RNN层堆叠在一起形成的。输入序列首先被送入第一层RNN,第一层的输出然后被送入第二层,以此类推,直到最后一层。最顶层的输出可以用于序列生成、分类等任务。
深度RNN是由多个RNN层堆叠在一起形成的。输入序列首先被送入第一层RNN,第一层的输出然后被送入第二层,以此类推,直到最后一层。最顶层的输出可以用于序列生成、分类等任务。
这些循环单元可以是标准的RNN模型,也可以是GRU模块或LSTM模块。你也可以构建双向RNN的深度版本。由于深度RNN在训练上非常消耗计算资源,并且通常已经具有大的时间范围,因此你并不会像在常规深度神经网络中那样看到大量的深度循环层。
深度RNN扩展了基本RNN的概念,通过堆叠多个隐层来增加模型的深度。尽管它带来了更好的性能,但也带来了训练上的挑战。理解其结构、优势和局限性有助于我们在序列建模任务中做出更明智的决策。
总结
随着数据的不断增长和应用的不断拓展,序列模型在各种场景中都发挥着至关重要的作用。从最初的基础RNN到更先进的LSTM、GRU和双向RNN,每一种技术都在努力解决特定的问题,并在不同的应用中找到了它们的位置。
RNN及其变体通过捕获时间序列数据的内在模式,使得我们能够在语音识别、机器翻译、情感分析等任务上取得显著进展。但这些模型并不是无懈可击的;它们有自己的缺陷,如梯度消失和爆炸问题,需要我们采用特定技术和策略进行优化。
深度RNN进一步拓展了模型的能力,允许我们捕获更复杂的模式和特征。但随之而来的是更大的计算负担和训练难度。
总的来说,理解这些模型的工作原理、优点和局限性对于AI和机器学习工程师来说是必不可少的。只有深入了解这些工具,我们才能够更好地利用它们,解决实际问题,推动技术的进步。