本周的内容主要是一些优化算法的知识点,这些优化算法可以帮助我们更好更快速的训练一个深度学习模型,Let’s Go!
1. 优化算法的重要性
优化算法在机器学习和深度学习领域起着关键的作用,特别是在训练深度神经网络时。它们是用于最小化(或最大化)函数的一种策略或者说是方法。在深度学习中,这个函数通常是损失函数,优化的目标是找到使得这个函数值最小的参数。
为什么我们需要优化算法
在深度学习中,我们的目标是使模型在训练数据上的表现尽可能好,同时避免过拟合,使得模型在未见过的数据上也能表现良好。这就涉及到一个权衡问题,我们需要找到一个平衡点,使得模型既不会过拟合也不会欠拟合。优化算法就是帮助我们找到这个平衡点的工具。
常见的优化算法类型
- 批量梯度下降:每次迭代使用所有的训练样本来进行梯度下降。
- 随机梯度下降:每次迭代只使用一个训练样本进行梯度下降。
- 小批量梯度下降:每次迭代使用一部分训练样本进行梯度下降。
优化算法的选择是非常重要的,选择适合的优化算法能够提高模型的性能和准确性,同时还能减少训练时间。在接下来的内容中,我们将详细讨论一些重要的优化算法,并解释它们的工作原理。
2. 小批量梯度下降
梯度下降是最常用的优化算法之一,其主要目标是最小化一个给定的函数(在深度学习中,这通常是损失函数)。这个过程通过迭代地调整模型的参数来实现,使得每次迭代后,损失函数的值都有所下降。为了做到这一点,参数更新的方向总是朝向损失函数梯度的反方向,也就是说,我们朝着使损失函数下降最快的方向前进。
小批量梯度下降(Mini-batch Gradient Descent)介于批量梯度下降(Batch Gradient Descent)和随机梯度下降(Stochastic Gradient Descent)之间。在批量梯度下降中,我们使用整个训练集来计算每次迭代的梯度,而在随机梯度下降中,我们仅使用一个样本来计算每次迭代的梯度。小批量梯度下降每次迭代则使用一部分样本(也就是一个“小批量”)来计算梯度。
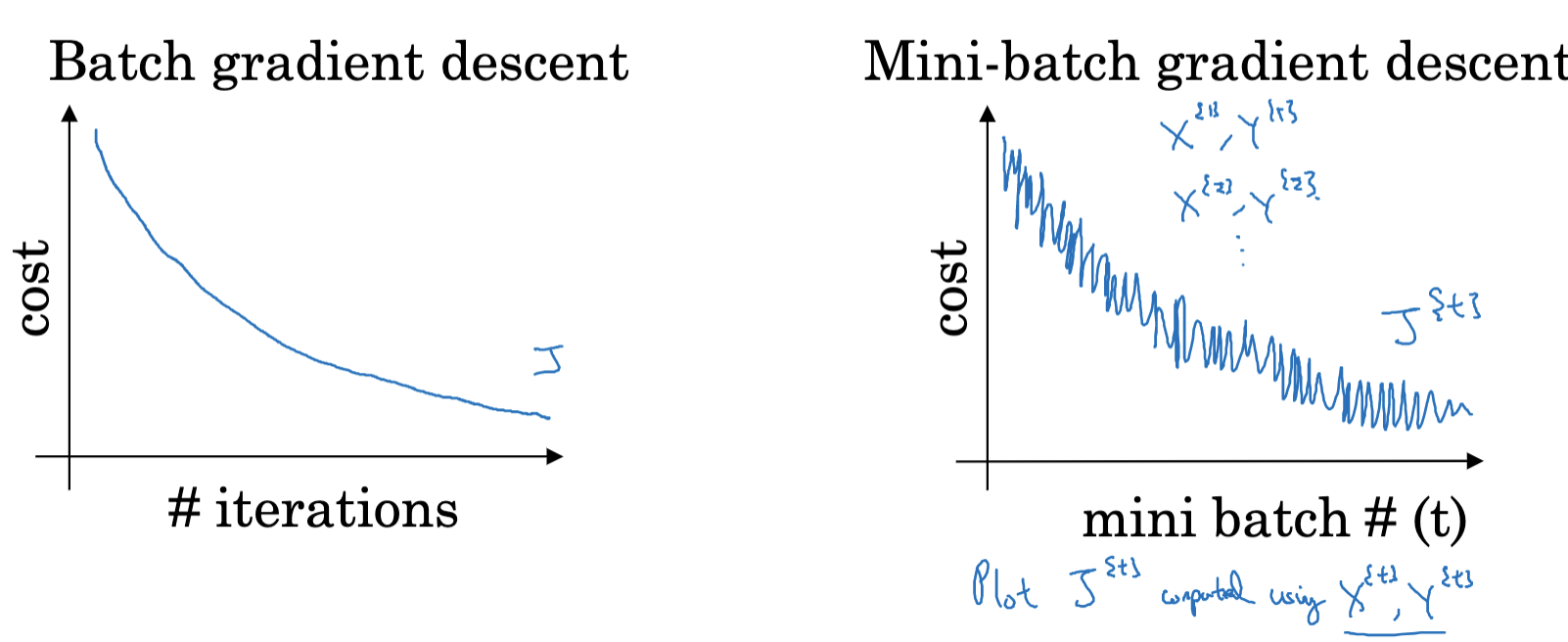
小批量梯度下降的主要优点在于,它在批量梯度下降的稳定性和随机梯度下降的高效性之间取得了一个平衡。具体来说,小批量梯度下降可以利用矩阵运算的硬件优化来实现高效计算,同时,由于每次迭代只使用一部分样本,这增加了迭代过程中的随机性,有助于模型跳出局部最小值,从而可能找到更好的优化结果。
三种梯度下降的方式的对比如下:
- 批量梯度下降(Batch Gradient Descent):在每次迭代中,我们使用整个训练集来计算梯度并更新模型参数。这种方法可能会在每次迭代中花费大量时间,特别是在处理大型数据集时。
- 小批量梯度下降(Mini-batch Gradient Descent):在这种方法中,我们仅使用训练集的一部分(即一小块或"mini-batch")来计算梯度并更新模型参数。每次迭代的代价函数可能会有些许噪声,但总体趋势应该是下降的。我们需要设置合适的mini-batch大小,过大或过小都会影响模型训练的效率。
- 随机梯度下降(Stochastic Gradient Descent):这种方法的极端情况是每次迭代只使用一个训练样本来计算梯度并更新模型参数。这种方法可能会有很大的噪声,并且不一定会收敛到全局最小值,但通常可以大致方向正确。
关于Mini-batch大小的选择:
- 如果训练集较小(例如,少于2000个样本),使用批量梯度下降是合适的。
- 对于较大的训练集,mini-batch的大小一般选在64到512之间。这是因为计算机的内存访问方式使得2的幂数的mini-batch大小更为高效(例如64,128,256,512)。
- 需要确保每个mini-batch的数据能够放入CPU/GPU的内存中。
3. 指数加权平均的概念和实践
在优化算法中,我们常常需要估计某些参数或者统计量的移动平均。在这种情况下,我们可以使用一种叫做指数加权平均(Exponentially Weighted Averages)的技术。在统计学中也被称为指数加权滑动平均。
指数加权平均的概念
指数加权平均背后的主要思想是赋予近期的观测值更大的权重,而赋予远期的观测值较小的权重。具体来说,给定一系列的观测值 x_1, x_2, \ldots, x_t,对于每个时间步 t,我们可以计算指数加权平均 V_t 如下: V_t = \beta V_{t-1} + (1 – \beta)x_t 在这个公式中,\beta 是一个在0和1之间的参数,决定了权重分布的程度。\beta 越接近1,我们赋予过去观测的权重就越大,即平均值变化更加平稳,图像上曲线更加平滑;\beta 越小,权重就更加偏向于最近的观测值,平均值变化更加敏感。
指数加权平均的实现
当t=100, \beta=0.9时,我们可以理解为0.1x_{100}+0.9x_{99} ,那么可以得到V_{100}实际上是前面99,98等一系列数值的加权平均,权重系统以0.9的幂递减。实际上,这些系数的和接近于1,这也是为什么成为指数加权平均。
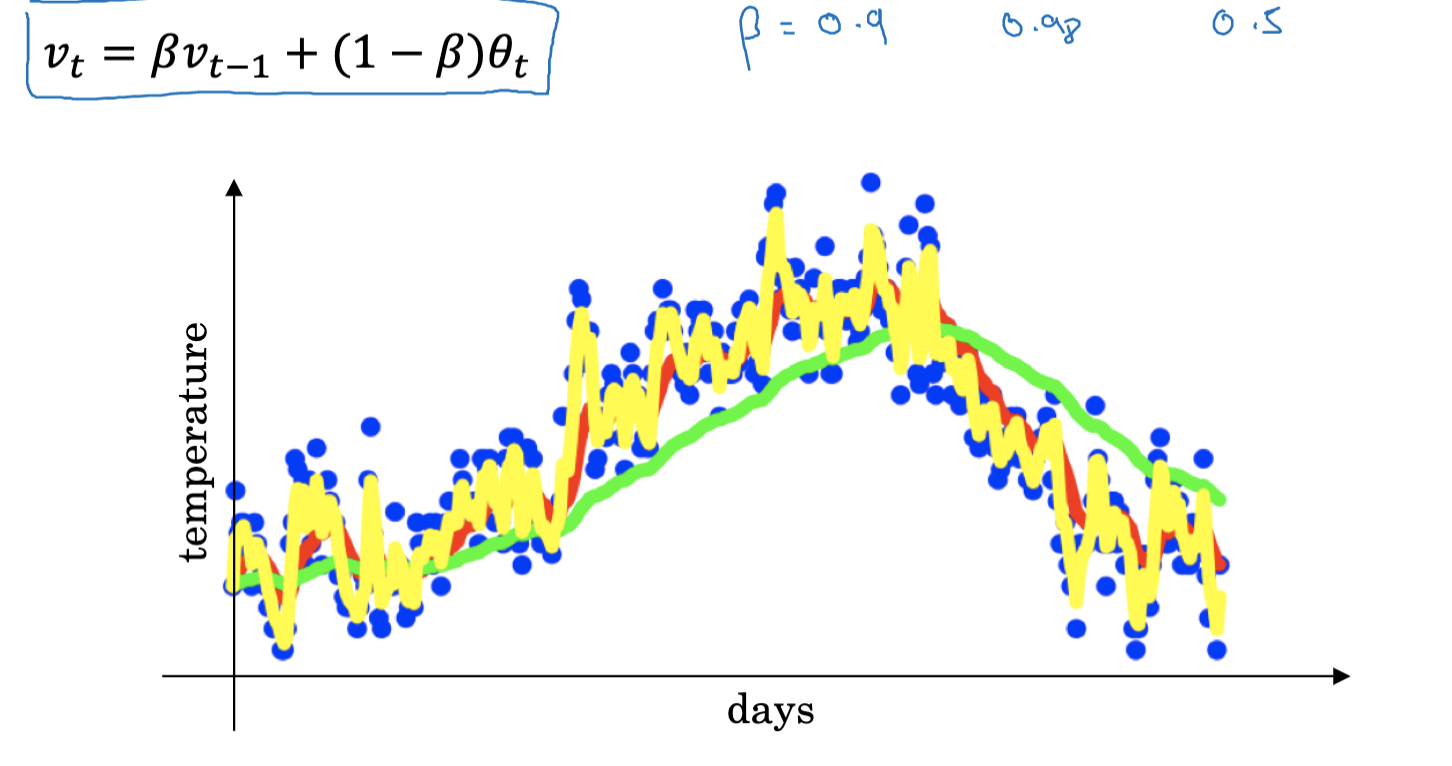
那么,指数加权平均实际上是对多少天的数据进行平均呢?如果 \beta=0.9 ,那么 0.9 的10次幂约为0.35,也就是说,权重在10天后就已经衰减到当天权重的1/3左右。因此,我们可以说,当 beta=0.9 时,这个公式实际上是在计算最近10天的数据的加权平均。 相反,如果 \beta=0.98 ,那么需要50天的时间,权重才会衰减到当天权重的1/3左右。因此,我们可以将这个公式视为在计算最近50天的数据的加权平均。总的来说,我们可以认为这个公式在大约1/(1-\beta)天的数据上求平均。
在实现指数加权平均时,我们需要初始化一个值 V_0,然后对于每个时间步 t,我们使用上面的公式来更新 V_t。在这个过程中,没有必要保存所有的观测值 x_i,我们只需要保存最新的 V_t 就可以了。这种方法的优点是它占用的内存非常少,只需要保留一个实数。这并不是最准确的求平均方法,如果你真的需要最准确的平均值,你应该计算一个滑动窗口内的所有值的平均,但是这需要更多的内存,也更复杂。而在许多需要计算大量变量平均值的场合,如深度学习,使用指数加权平均既高效又节省内存。
偏差产生的原因与偏差修正
然而,指数加权平均有一个小问题,那就是在初期阶段,由于 V_0 的初始化和加权平均的特性,它会有一些偏差。具体来说,当我们开始计算平均值时,平均值会偏向于初始值 V_0,而不是真实的平均值。解决这个问题的一种方法是使用偏差修正。 \hat{V}_t = \frac{V_t}{1-\beta^t}
在这个公式中,\hat{V}_t 是修正后的平均值,t 是时间步。当 t 较小的时候,\beta^t 会接近于1,所以修正项 1 – \beta^t 会较小,修正后的平均值 \hat{V}_t 会增大,从而减少了初期的偏差。当 t 越来越大,\beta^t 会接近于0,所以修正项 1 – \beta^t 会接近于1,修正后的平均值 \hat{V}_t 会接近于未修正的平均值 V_t。
4. 动量梯度下降(Momentum Gradient Descent)
梯度下降算法的一个常见问题是,如果损失函数的形状不平衡,也就是说,在某一方向上比另一方向上陡峭很多,那么梯度下降算法可能会非常缓慢。动量梯度下降通过引入“动量”概念,尝试解决这个问题。
基本思想
动量梯度下降的思想来源于物理学,其中一个物体下坡的速度不仅取决于当前的坡度(即梯度),还取决于其过去的速度(即动量)。在优化的上下文中,我们可以将过去的梯度视为速度,将它们的指数加权平均视为动量。
当我们试图优化一个具有类似椭圆形轮廓的成本函数时,标准的梯度下降算法可能会在垂直轴上产生很多上下震荡,这样会减慢梯度下降的速度。我们不能使用太大的学习率,因为这可能会导致算法在椭圆形轮廓的一侧和另一侧之间“跳跃”,而无法收敛。
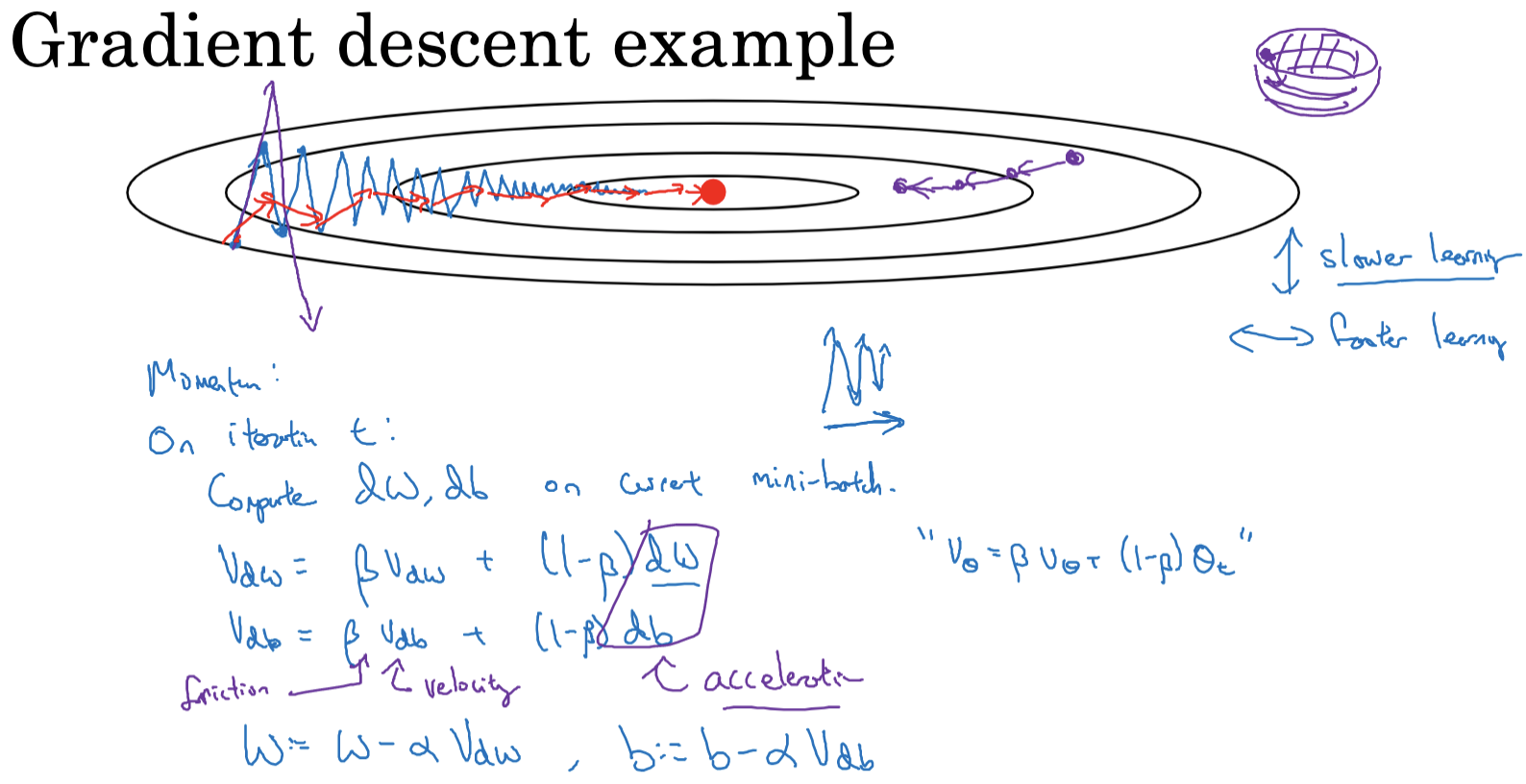
为了解决这个问题,我们可以使用动量梯度下降法。在每一次迭代中,我们会计算常规的导数dw和db(使用当前的mini-batch或者全体数据集)。然后,我们计算梯度的指数加权平均值vdw和vdb。权重的更新不再使用原始的dw和db,而是使用vdw和vdb。这样就可以平滑梯度下降的步长,减少垂直方向的震荡,同时加快水平方向的移动。
优点
动量梯度下降的一个主要优点是,它可以加快梯度下降在平坦方向上的速度,同时抑制在陡峭方向上的震荡。这是因为,在平坦方向上,由于梯度较小,所以过去的梯度会起主导作用,从而加速了参数在这个方向上的移动。在陡峭方向上,虽然当前梯度较大,但是由于过去的梯度有正有负,所以它们的平均值较小,从而抑制了参数在这个方向上的移动。
5. RMSprop优化算法
RMSProp(Root Mean Square Propagation)是一种改进的梯度下降算法,它通过调整学习率来加速优化过程。这种方法的思想是,如果一个参数在过去的迭代中经常改变,那么我们应该减小它的学习率;相反,如果一个参数在过去的迭代中很少改变,那么我们应该增大它的学习率。RMSprop 并不是在学术论文中被首次提出,而是在 Geoffrey Hinton 的 Coursera 课程中首次提到的。
RMSprop 算法流程
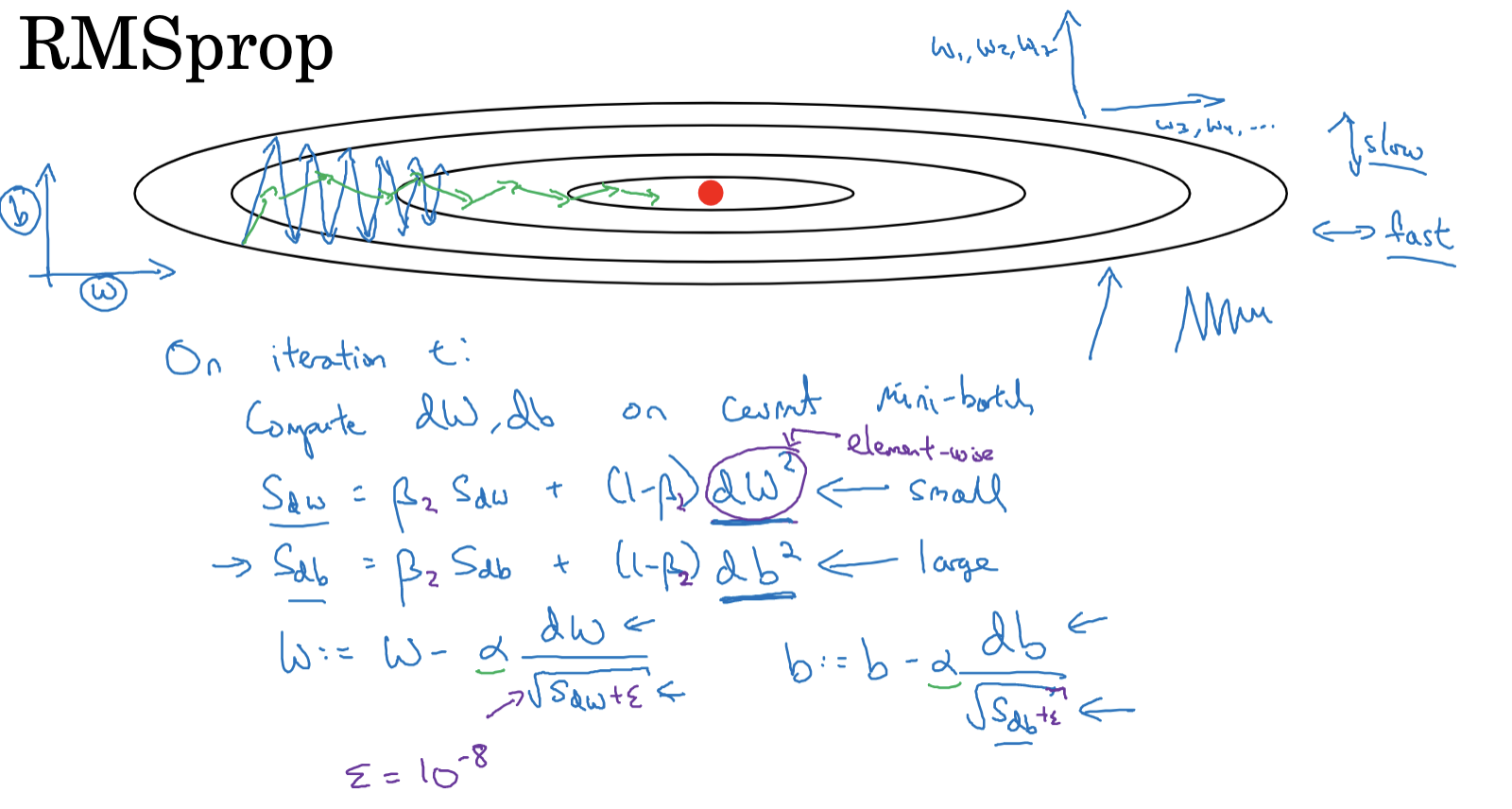
- 在第t次迭代中,像往常一样计算当前小批量的梯度dW和db。
- 计算梯度的平方的指数加权平均数。更新公式如下:
- $S_{dW} = \beta S_{dW} + (1-\beta)_(dW)^2$
- $S_{db} = \beta S_{db} + (1-\beta) * {db}^2$ 其中,β是一个介于0和1之间的超参数,这个平方操作是逐元素的平方操作。
- 更新参数,公式如下:
- $W = W – \alpha*(dW/\sqrt{S_{dW}})$
- $b = b – \alpha*(db/\sqrt{S_{db}})$其中,α是学习率,这里除以的是$S_{dW}$和$S_{db}$的平方根,而不是仅仅使用梯度。
RMSprop 工作原理解析
- 在RMSprop中,我们希望在不同的方向上有不同的更新速度。例如在一些维度(例如参数b)上,我们希望学习速度慢一些以减少振荡;而在另一些维度(例如参数W)上,我们希望学习速度快一些以加快收敛。
- 为了达到这个目的,RMSprop利用了梯度的平方。如果某个方向(例如参数b)上的梯度绝对值较大,那么其平方就会很大,那么S_{db}就会较大,导致这个方向上的更新速度降低。反之,如果某个方向(例如参数W)上的梯度绝对值较小,那么其平方就会较小,那么S_{dW}就会较小,导致这个方向上的更新速度加快。
- 为了避免除零错误,我们会在分母加上一个非常小的数 \epsilon,常见值为10^{-8}。
- 为了区别动量中的超参数β,这里的超参数常被命名为β2。
和动量梯度下降对比
和动量梯度下降相比,RMSprop在处理不同方向梯度尺度差异大的问题上更具优势。动量梯度下降主要通过加快梯度改变较小的方向来加速收敛,而RMSprop则是通过对每个参数进行单独的学习率调整,使得所有参数都能以合适的速度进行更新。
6. Adam优化算法
Adam(Adaptive Moment Estimation)是一种改进的梯度下降算法,它结合了动量梯度下降和RMSprop的思想。Adam的主要优点是,它可以自适应地调整每个参数的学习率,使得在不同的情况下都能有良好的性能。
基本思想
Adam(自适应矩估计)是动量和RMSprop的结合。以下是它的工作步骤: 1. 初始化:V_{dw}=0, S_{dw}=0, V_{db}=0, S_{db}=0 2. 在第t次迭代中,计算梯度dw,db,并计算动量指数加权平均 1. $V_{dw}=\beta_1V_{dw}+(1-\beta_1){dw}2.V{db}=\beta_1V_{db}+(1-\beta_1)db。 4. 更RMSprop一样去更新 1.S_{dw}=\beta_2S_{dw}+(1-\beta_2){dw}^22.S{db}=\beta_2S_{db}+(1-\beta_2){db}^25. 对V和S进行偏差修正 1.V_{dw}^{corrected}=V_{dw}/(1-\beta_1^t), 2.V_{db}^{corrected}=V_{db}/(1-\beta_1^t)3.S_{dw}^{corrected}=S_{dw}/(1-\beta_2^t)4.S_{db}^{corrected}=S_{db}/(1-\beta_2^t)。 6. 执行参数更新 1.W=W-\alpha * V_{dw}^{corrected}/(\sqrt{S_{dw}^{corrected}}+\epsilon)2.b=b-\alpha*V_{db}^{corrected}/(\sqrt{S_{db}^{corrected}}+\epsilon)$。
学习率\alpha需要调整,通常的做法是尝试一系列的值。推荐的默认值是\beta_1=0.9, \beta_2=0.999,\epsilon=10^{-8}。在实施Adam时,通常会尝试一系列的\alpha值。\beta_1和\beta_2也可以调整,但这并不常见。
Adam代表自适应矩估计(Adaptive Moment Estimation)。\beta_1用于计算梯度的平均值(第一矩),\beta_2用于计算梯度平方的指数加权平均(第二矩)。
这个优化算法结合了带动量的梯度下降和带RMSprop的梯度下降的优点,已被证明在许多不同的神经网络架构中都非常有效。
7. 学习率衰减(Learning Rate Decay)
在许多优化算法中,我们都需要设置一个学习率参数,它决定了参数更新的幅度。如果学习率太大,那么优化过程可能会在最优点附近震荡,无法收敛;如果学习率太小,那么优化过程可能会非常缓慢。学习率衰减是一种常见的技巧,可以帮助我们在训练过程中动态调整学习率。
基本思想
学习率衰减的基本思想是,随着训练的进行,我们逐渐减小学习率。这样可以使得在训练初期,当我们离最优点还很远时,可以用较大的学习率快速接近;然后在接近最优点时,用较小的学习率进行精细调整,避免在最优点附近震荡。
实现方法
有许多方法可以实现学习率衰减,以下是其中的几种:
-
时间衰减:这是一种常见的学习率衰减方法,其思想是随着训练步数的增加,学习率线性或指数地减小。例如,我们可以设置学习率为 \alpha / (1 + t / T),其中 \alpha 是初始学习率,t 是当前步数,T 是一个超参数。
-
步长衰减:在这种方法中,我们每训练一定的步数,就将学习率减小一定的比例。例如,我们可以设置每训练1000步,就将学习率乘以0.9。
-
预定衰减:在这种方法中,我们事先设定一个学习率的衰减计划,然后按计划进行学习率衰减。例如,我们可以设置前1000步学习率为0.01,然后下一个1000步学习率为0.001,以此类推。
8. 局部最优问题
在优化过程中,我们经常遇到的一个问题是局部最优。局部最优是指在参数空间中,某个区域内的最优点,但并不是整个参数空间的最优点(即全局最优)。如果我们的优化算法停在了局部最优,那么我们就得不到最好的模型性能。
局部最优与深度学习
然而,在深度学习中,尽管局部最优看起来是一个问题,但实际上,它并不是那么严重。这是因为在高维空间中,大部分局部最优点其实是“鞍点”。在鞍点,一部分方向上是局部最优,但在另一部分方向上,可能还可以进一步优化。由于深度学习模型通常有大量的参数,所以即使在局部最优,我们仍然有很大概率能够找到一个可以优化的方向,从而跳出局部最优。
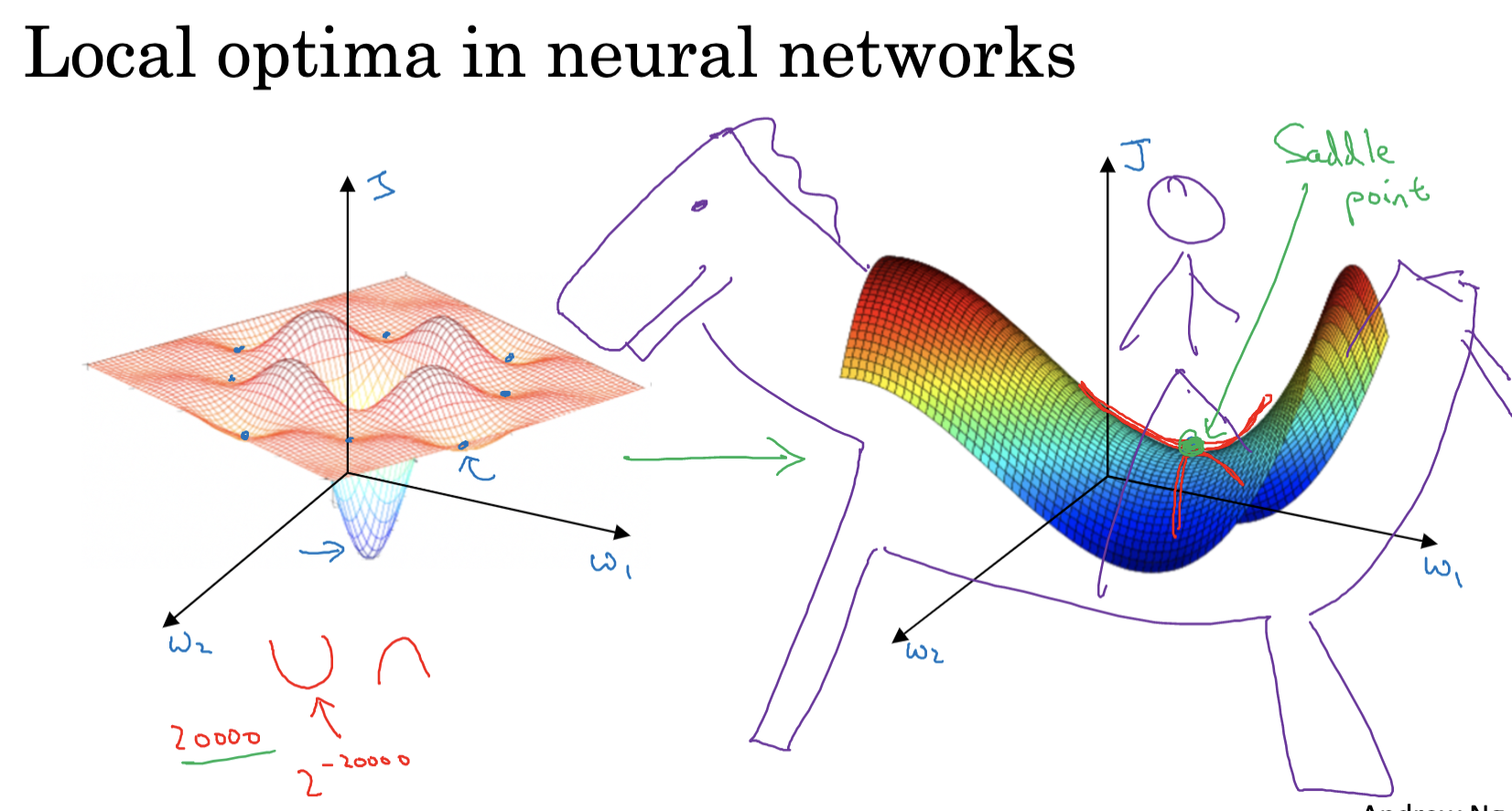
此外,许多优化算法,如动量梯度下降、RMSprop和Adam,都有助于我们跳出局部最优。它们通过累积过去的梯度,可以帮助我们沿着梯度改变较小的方向进行搜索,从而有可能找到一个可以优化的方向。
随机性和局部最优
随机性也有助于我们跳出局部最优。在深度学习中,由于我们通常使用小批量梯度下降,所以每一步的梯度都有一定的随机性。这意味着,即使我们在局部最优,也可能由于随机的梯度而跳出局部最优。此外,我们还可以通过添加噪声或使用随机的初始化方法,来增加优化过程的随机性,从而有更大的机会跳出局部最优。
在这篇博客中,我们已经介绍了许多深度学习优化的知识,包括小批量梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam、学习率衰减和局部最优问题。希望这些知识能帮助你在深度学习的旅程中更好地进行模型训练, 虽然本章公式有点多,但记不住也没关系,后续开发过程会使用各种机器学习框架辅助开发,而不需要手动去计算这些公式。感谢你的阅读,我们在下一篇博客中再见!