微软在10.26日发表了一篇论文CODEFUSION: A Pre-trained Diffusion Model for Code Generation,主要内容是提出了一个叫做CodeFusion的模型,它是一个基于扩散模型的从自然语言到代码生成模型,相对于论文提到的这个模型,更劲爆的是论文中的一张表格: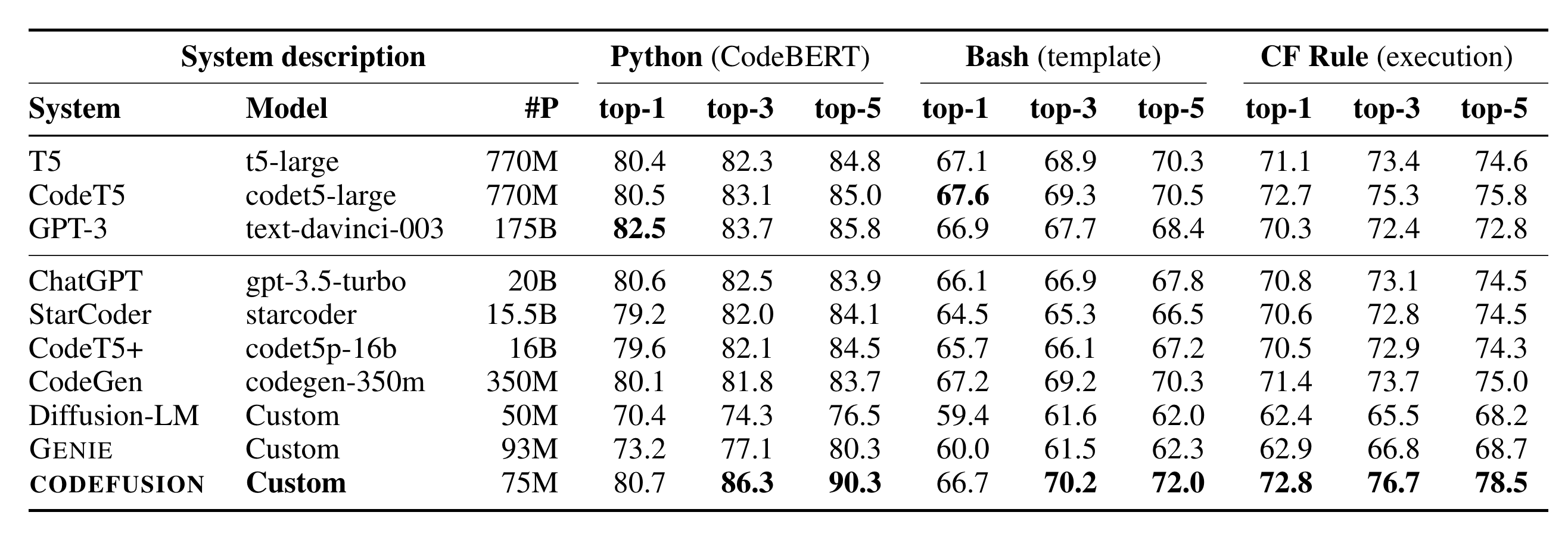
看到图中的System description中出现的GPT-3和ChatGPT了么,尤其是gpt-3.5-turbo,模型大小仅仅只有20B,作为一直封闭着不透露任何模型内部消息的ChatGPT,这次不知是否是故意,在论文的实验结果中给出了ChatGPT的模型大小。对于这个数据的真实性,虽然没有官方直接的声明,但我个人认为是可靠的,而且大家如果有看OpenAI的官方API文档的话,也能看到对于gpt-3.5-turbo的说明,3.5的成本只有text-davinci-004的十分之一。

不过虽然3.5的模型大小只有20B,但我想它应该不是直接训练一个20B的模型,而是先有一个大模型然后通过蒸馏等手段缩小到20B,而20B的大小对于硬件部署成本要低得多,现在炼制模型给很多人的感觉就是大力出奇迹,参数越多越好,但通过3.5只有20B这个结果可以看出,生产可使用的模型大小也许并不是非得要那么巨大的参数数量,质量比数量更加重要。
话说回这篇论文本身,我也没仔细看,就简单用ChatGPT4来进行了一下摘要,这篇论文主要解决的问题是:自回归模型在代码生成中不能轻易地重新考虑先前生成的令牌,这可能导致生成的代码缺乏多样性。因此提出了CODEFUSION,一个预训练的扩散代码生成模型,它通过迭代地去噪一个完整的程序来解决这个问题,该程序是在编码的自然语言的条件下生成的。实验方式简单地说就下面几步(来源GPT4):
- 使用编码器-解码器架构与扩散过程相结合。
- 编码器将自然语言映射到一个连续的表示形式。
- 扩散模型用于去噪随机高斯噪声输入。
- 使用一个transformer解码器生成语法正确的代码
此外,最近OpenAI对于ChatGPT4又出了重磅更新,再也不需要在下拉框上选择Browse with Bing, DALLE3这种只能选一种能力来使用GPT4了,而是直接同时支持使用这些功能,并且还支持PDF文件上传了!
不过目前这项功能应该只提供给了部分用户,未来应该会逐步向所有GPT4用户开放,上面论文的分析我用的是GPT4的插件实现的,但用起来不如Claude2方便,可是Claude2的总结往往不太令我满意,因此我如果使用AI工具辅助我进行论文阅读时,我往往需要GPT4和Claude2来回切换,看看两者的说明,然后自己浏览一遍论文,特别喜欢的论文就精读几遍,然后有疑问再问GPT,等后面推送了All-in-One的能力后,我想对于我这种非专业学术人士但又喜欢看看论文的人来说,要方便很多。下周(11月6日),OpenAI将要举办首届开发者大会,不知到时候又会爆出什么新的花样呢?