Building and better understanding vision-language models: insights and future directions 构建与深化理解视觉-语言模型:洞察与未来方向 视觉-语言模型 (VLMs) 领域,以图像和文本为输入并输出文本,正处于快速发展阶段,但在数据、架构和训练方法等关键开发环节上…
xGen-MM (BLIP-3): A Family of Open Large Multimodal Models xGen-MM (BLIP-3): 一个开放的大型多模态模型家族 本报告介绍了 xGen-MM(又称 BLIP-3),这是一个用于开发大型多模态模型(LMMs)的框架。该框架整合了精心策划的数据集、训练方案、模型架构以及一系列由此产…
VITA: Towards Open-Source Interactive Omni Multimodal LLM VITA:迈向开源交互式全模态大语言模型 GPT-4o 的卓越多模态能力和交互体验,凸显了其在实际应用中的重要性,但开源模型在这两个领域的表现往往不尽人意。本文介绍的 VITA,是首个开源的多模态大语言模型(MLLM),能够同时处理和…
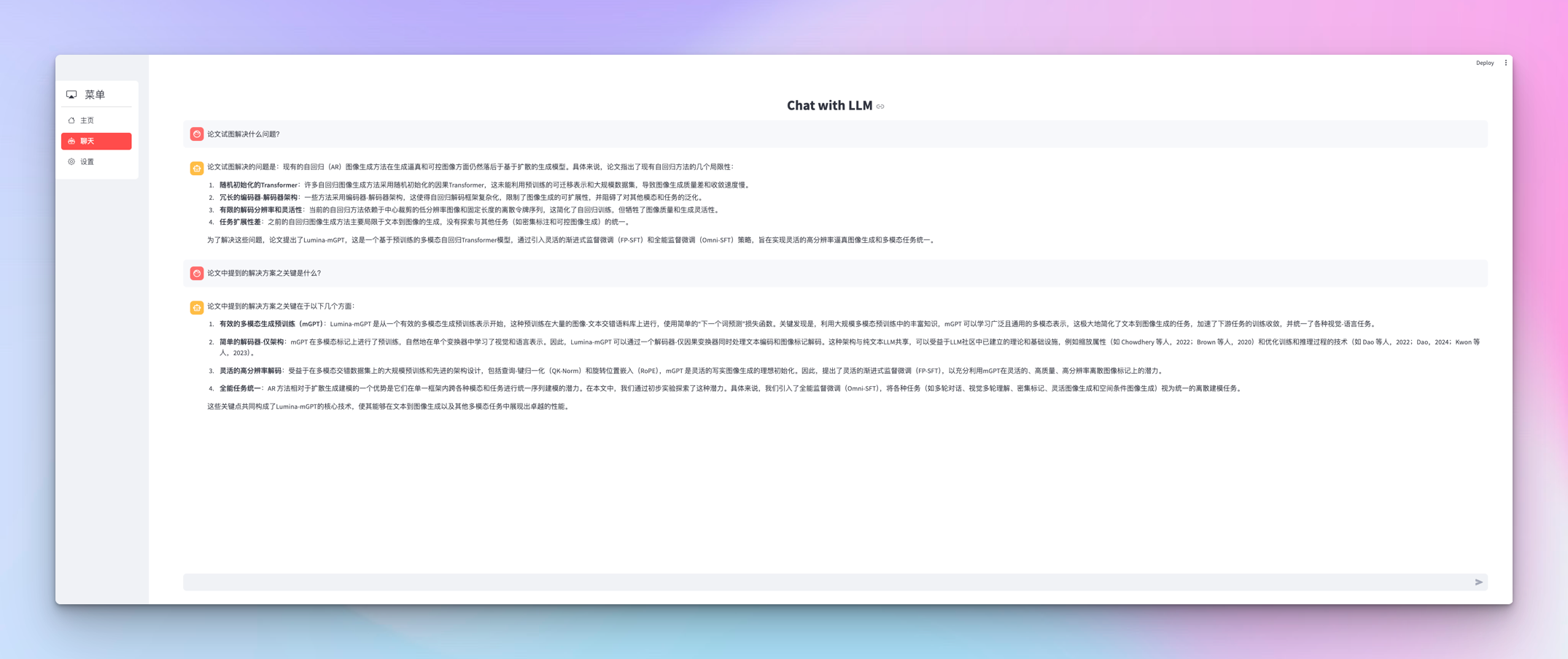
Paper-Agent支持论文问答转聊天功能

本周有点偷懒,没想好写什么技术文章,就给Paper-Agent加了点花样,支持基于首页的论文问答进行对话,直接切换到聊天菜单就会自动带上。目前只做了Deepseek的适配,当然理论上所有的符合OpenAI规范的模型都可以适配,只是还未经过测试,不能保证。 因为Deepseek上周支持了硬盘缓存,因此这种比较耗费token的聊天也能节省大量的成本了,…

Medical SAM 2: Segment medical images as video via Segment Anything Model 2 Medical SAM 2: 利用 Segment Anything Model 2 实现医学图像的视频化分割 本文介绍 Medical SAM 2 (MedSAM-2),一种先进的分割模型,采用 …
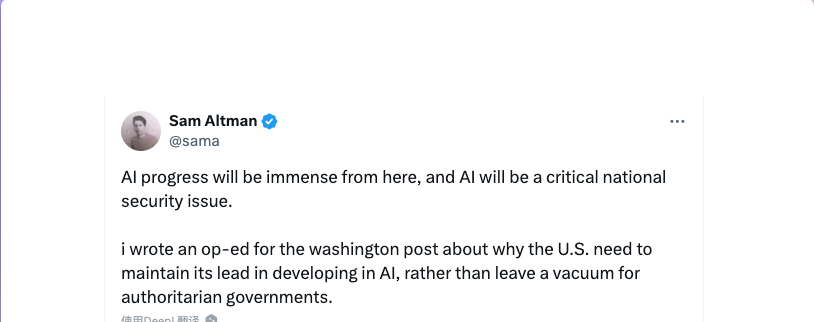
今天随便翻了翻X,看到了 Sam Altman 7月底发的一篇推文,说的是他在 Washington Post 上的一篇文章,Who will control the future of AI? ,从他说的 U.S. need to maintain its lead in developing in AI 来看,就显然可以看出他不会是那种希望全球…

每周AI论文速递系列已经创建GitHub仓库,欢迎star. SHIC: Shape-Image Correspondences with no Keypoint Supervision SHIC: 无关键点监督的形状-图像对应关系 规范表面映射通过将对象的每个像素分配到3D模板中的对应点,从而拓展了关键点检测的应用范围。DensePose在分析人…
关于之前翻译的UDL一书,之前一直没注意原版的书籍的开源协议问题,协议是知识共享许可协议(Creative Commons license, 简称CC协议),但这本书的完整版权组合是Creative Commons Attribution-NonCommercial-NoDerivatives 4.0(CC BY-NC-ND 4.0)。 对于这本…
Internal Consistency and Self-Feedback in Large Language Models: A Survey 大语言模型中的内部一致性与自反馈:一项调查 大语言模型 (LLMs) 本应提供准确答案,但往往出现推理不足或生成虚构内容的问题。为此,一系列以“自-”为前缀的研究,如自一致性 (Self-Consist…

之前写的Paper-Agent最近做了些重构升级,主要是下面这些变动: 多种大模型的支持 之前是只接入了 deepseek 和 kimi, 并且使用 Kimi 作为pdf问答的关键大模型,但经过使用后发现一个比较头疼的问题,kimi 的api略贵了一点,如果要做完整的论文十问可能要一块多,但官方有个 Context Caching 的功能,可以节约…