前不久李飞飞教授的"我看见的世界"中译版在中国发售了,我也迫不及待买了一本,这两周断断续续的看完了。看完后的感慨颇深,想着好好写一篇文章来分享给大家。 整本书阅读下来,对于我而言,最难以忘记的词汇就是“北极星”这个词,似乎这就是作者一生所努力的关键词,而这,也是普普通通的我们也同样需要追逐的。 波折而又幸运的成长过程 我在阅读这…
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning PLLaVA:图像至视频无参数扩展的 LLaVA 模型,用于视频详细描述 视觉-语言预训练显著提升了各种图像-语言应用的性能。然而,视频相关任务的预训练过程需巨大的计算和数…

论文解读:KAN: Kolmogorov–Arnold Networks
每周AI论文速递(240422-240426)
每周AI论文速递(240415-240419)

五一假期刚开始没两天的时候,刷到了一篇火遍国内外AI圈的论文,叫做 KAN: Kolmogorov–Arnold Networks , 尤其国内某些科技媒体铺天盖地的宣传更是让我提起了兴趣,在假期结束之前,抽个空读一下看看是怎么个事。读了之后发现,仅仅只是高数、线代和概率论这些数学知识是看不懂的,最好还需要了解一点数分方面的知识,反正我是借助了Ch…
AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation AutoCrawler: 一个为 Web 爬虫生成的渐进式理解 Web 智能体 Web 自动化是一种重要技术,它通过自动执行常见网页动作来处理复杂的网页任务,从而提高操作效率并减少手动干预。传统…
Pre-training Small Base LMs with Fewer Tokens 使用更少的 Token 对小型基础 LMs 进行预训练 我们研究了一种简单方法来开发一个小型基础语言模型 (LM),从一个现有的大型基础 LM 开始:首先从较大的 LM 继承一些 Transformer 块,然后在这个较小的模型上使用一个非常小的子集 (0.…
一文带你了解当前主流PEFT技术
每周AI论文速递(20240408-20240412)
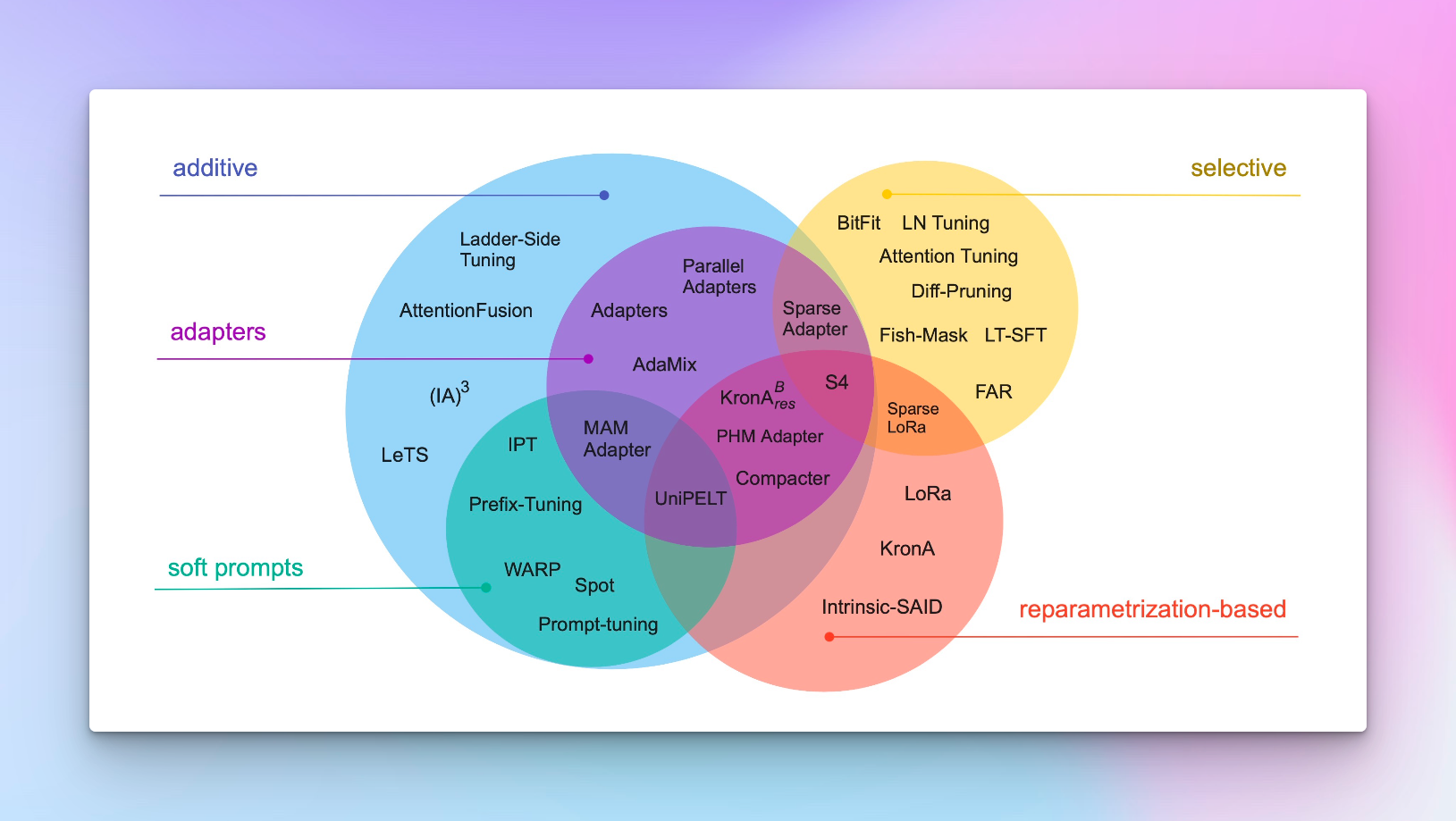
随着LLaMA3的发布,大模型开源社区的战力又提升了一分,国内目前应该已经有不少大佬已经开始着手对LLaMA3进行研究或微调,对于微调技术,目前比较常见的就是Peft系列的技术,那么什么是PEFT,有哪些分类,为什么这么受大家欢迎呢?今天我们就好好聊聊这个话题。 什么是PEFT? 有哪些技术? PEFT的全称叫做 Parameter-Efficie…
Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences 直接纳什优化:教授语言模型通过通用偏好自我提升 本文研究如何利用强大神谕的偏好反馈,对大语言模型 (大语言模型) 进行后训练,以帮助模型迭代地自我改进。传统的大语言模…

问答AI模型训练前的必做功课:数据预处理
每周AI论文速递(240401-240405)
每周AI论文速递(240325-240329)
翻译完了UDL这本书之后放松了一个多礼拜没有更新文章了,主要最近也在学习一些微调上面的知识,平时晚上还需要跑跑代码看看视频啥的,因此也一直没太有空写文章,UDL的翻译整理成PDF的工作都没空整。(虽然实际最近也花了很长时间在打游戏(。・_・。))。又到周末了,再拖着不干点正事我也过意不去了,今天就写点关于最近学习的一些关于微调方面的东西好了,因为我…
Jamba: A Hybrid Transformer-Mamba Language Model Jamba:混合 Transformer-Mamba 语言模型 我们推出了 Jamba,这是一种基于创新的混合 Transformer-Mamba 混合专家 (MoE) 架构的大型基础语言模型。Jamba 特别地将 Transformer 和 Mamb…
Can large language models explore in-context? 大语言模型能进行上下文探索吗? 我们研究了当代大语言模型(LLMs)在多大程度上能够进行探索,这在强化学习和决策制定中是一个核心能力。我们专注于现有LLMs的本质性能,不借助训练干预。我们在简单的多臂赌博机(multi-armed bandit)环境中部署L…