长期潜水在各个LLM技术群的小透明今天看到了智谱AI和清华团队又整了一篇有意思的论文,叫做Black-Box Prompt Optimization: Aligning Large Language Models without Model Training 主要是解决大模型的”对齐问题“。
啥叫对齐问题呢?指的是确保人工智能(AI)系统的目标、动机、决策与人类的价值观和目标保持一致的挑战。简单的说就是希望大模型做出的行为和人类想要的是一致的。这种不一致有很多后果,轻一点的就是胡说八道或者不按逻辑办事,严重一点甚至会脱离人类控制。那么对于我们最近用的比较多的LLM,我们更想做的是让LLM能更准确的回复我们的问题。
目前比较流行的几种方案
目前的对齐工作策略有下面这么几种:SFT、RLHF、Prompt Engineering and Prompt Tuning。
监督式微调(SFT)使大型语言模型具备了初步的遵循指令能力。不过,它极度依赖大量高质量的微调数据,虽然目前已经有一些研究可以减少数据集大小,但SFT对齐仍面临幻觉、可扩展性差和对人类偏好理解不足的问题。
从人类反馈中学习的强化学习(RLHF)旨在通过可扩展反馈进一步对齐大型语言模型。标准框架包括奖励建模(RM)和策略训练两个步骤。AI 反馈的强化学习与人类反馈的强化学习性能相似。考虑到复杂的程序和不稳定的强化学习训练,一些研究寻求超越 RLHF,通过其他方法学习偏好反馈。这方面的研究目前也已经有不少方案,但显然这种方案由于依赖人类反馈,人力成本也是比较高昂的。
提示工程和提示调整:提示调整分为硬提示调整和软提示调整两种。硬提示调整,即提示工程,通常需要大量手动工作。通过在嵌入空间而非限定词汇表中进行优化,进一步提高效率。软提示调整比全参数调整更快、更高效,同时保持了可比性能。
提示调整和模型训练一直是提升预训练模型性能的两种平行方式。目前的对齐策略都集中于调整模型以遵循用户意图和指令。在大型语言模型的背景下,模型变得庞大、难以训练或获取(例如基于 API 的模型)。因此论文的研究者们认为,优化输入提示同样重要,并且可以通过这种方式实现大型语言模型的对齐,而无需修改模型本身。
黑盒Prompt优化
下图是BPO的整体过程,它的主要目的是通过优化输入提示,增强模型输出与人类偏好之间的对齐。作者首先收集了带有人类偏好注释的指令调整数据集,并严格筛选去除低质量数据。接着利用大型语言模型来区分人类偏好和不偏好的响应,并基于此改善输入。然后,得到原始指令及其改进版本的数据对,使用这些数据来进一步训练一个序列到序列模型,以自动优化用户输入。

论文中认为,基于训练的对齐并非唯一解决方案。从根本上说,可以从两个方向缩小对齐差距:要么调整大型语言模型以适应人类偏好,要么改变人类的提示来迎合大型语言模型的理解。文中举了个简单的例子:提问LLM,“告诉我关于哈利·波特的事情”,这可能导致大型语言模型的简短回应。为了得到更详细和信息丰富的回应,虽然 RLHF 可通过训练大型语言模型实现这一目标,但使用者也可以通过修改用户提示为“提供关于哈利·波特系列的全面概述,包括书籍、电影、角色、主题和影响。请在你的回答中确保准确且提供丰富信息”来达成同样的目的。
为了实现优化用户输入,文中将用户输入定义为
为构建优化提示,研究人员们收集了带有人类偏好的数据集,还使用了GPT4生成数据集的比较子集。后面还经过人工精心筛选高质量的数据,得到了14000多条样本。接着使用ChatGPT精炼指令,最终经过一系列的过滤和处理,得到14000对优化前后的指令对。
基于构建好的数据集,本研究学习了一个小型序列到序列模型来自动优化用户指令。就是在给定的输入 X_user 上生成条件优化的 X_opt,损失函数定义为:
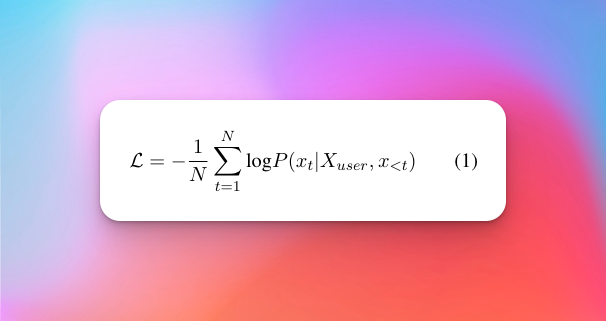 其中 N 是 X_opt 的长度,x_t 表示 X_opt 中的第 t 个 token。本次研究用的基础模型是llama2-7b-chat。
其中 N 是 X_opt 的长度,x_t 表示 X_opt 中的第 t 个 token。本次研究用的基础模型是llama2-7b-chat。
实验结果
从实验结果上看,BPO对齐技术对 GPT-3.5-turbo 有20%以上的提升,对 GPT-4 也有 10% 的提升。除此之外,这个方法在不同能力的模型中均取得一致的收益,从较小的开源模型如 llama2-7b-chat 和 vicuna-7b 到强大的大规模模型如 gpt-4 和 claude-2,展示了 BPO 对各种模型的强大泛化能力。
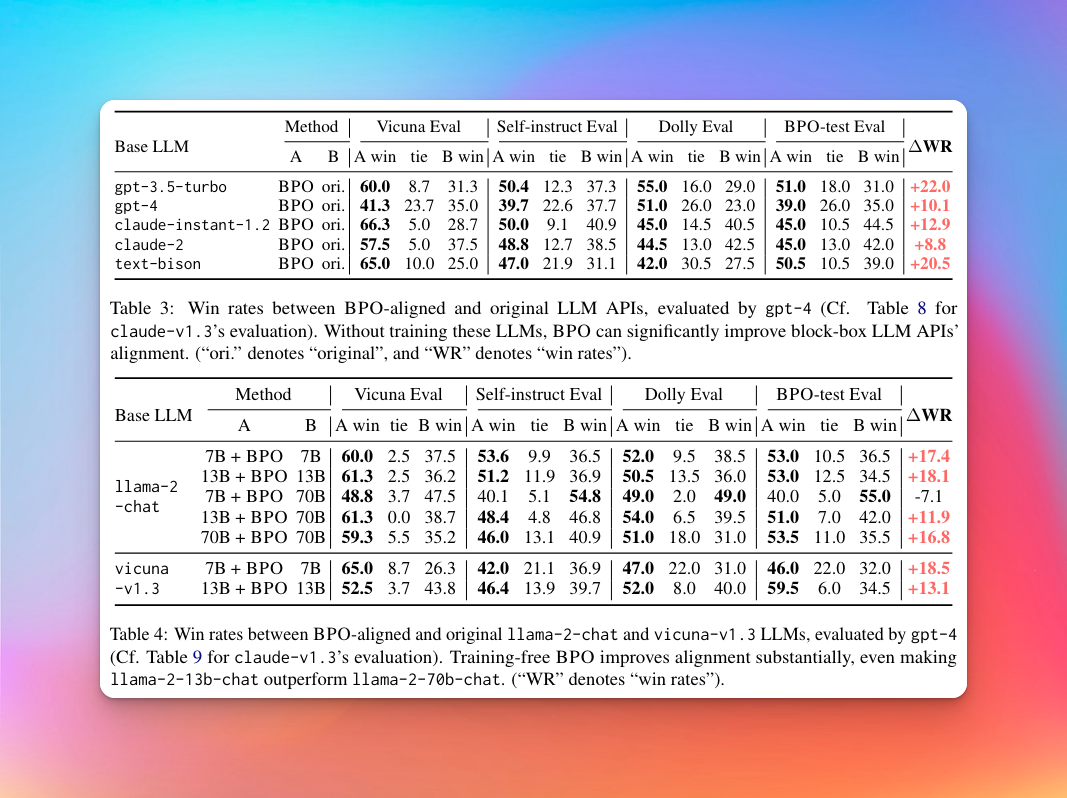
值得注意的是,BPO 使较小的模型 llama2-7b-chat 能够匹敌甚至在一些数据集上超过 10 倍大的模型。在 Claude 的评估下,使用 BPO 对齐的 llama2-7b-chat 几乎达到了 llama2-70b-chat 的性能。对于 llama2-13b-chat 模型,BPO 使其显著超越了 70b 模型,展示了 BPO 提升较小模型超越更大模型的潜力。
从RLHF的结果来看,PPO、DPO和BPO都成功提高了vicuna-7b和vicuna-13b的性能。BPO优化的SFT模型表现优于PPO和DPO优化的模型。
除此之外,在数据增强、迭代提示优化、其他提示工程方法比较的实验对比上,BPO都取得了良好的表现。因此总体来说,这些实验结果表明BPO是一个强大且有效的策略,可以提高不同规模和能力的大型语言模型在多个任务和数据集上的性能。
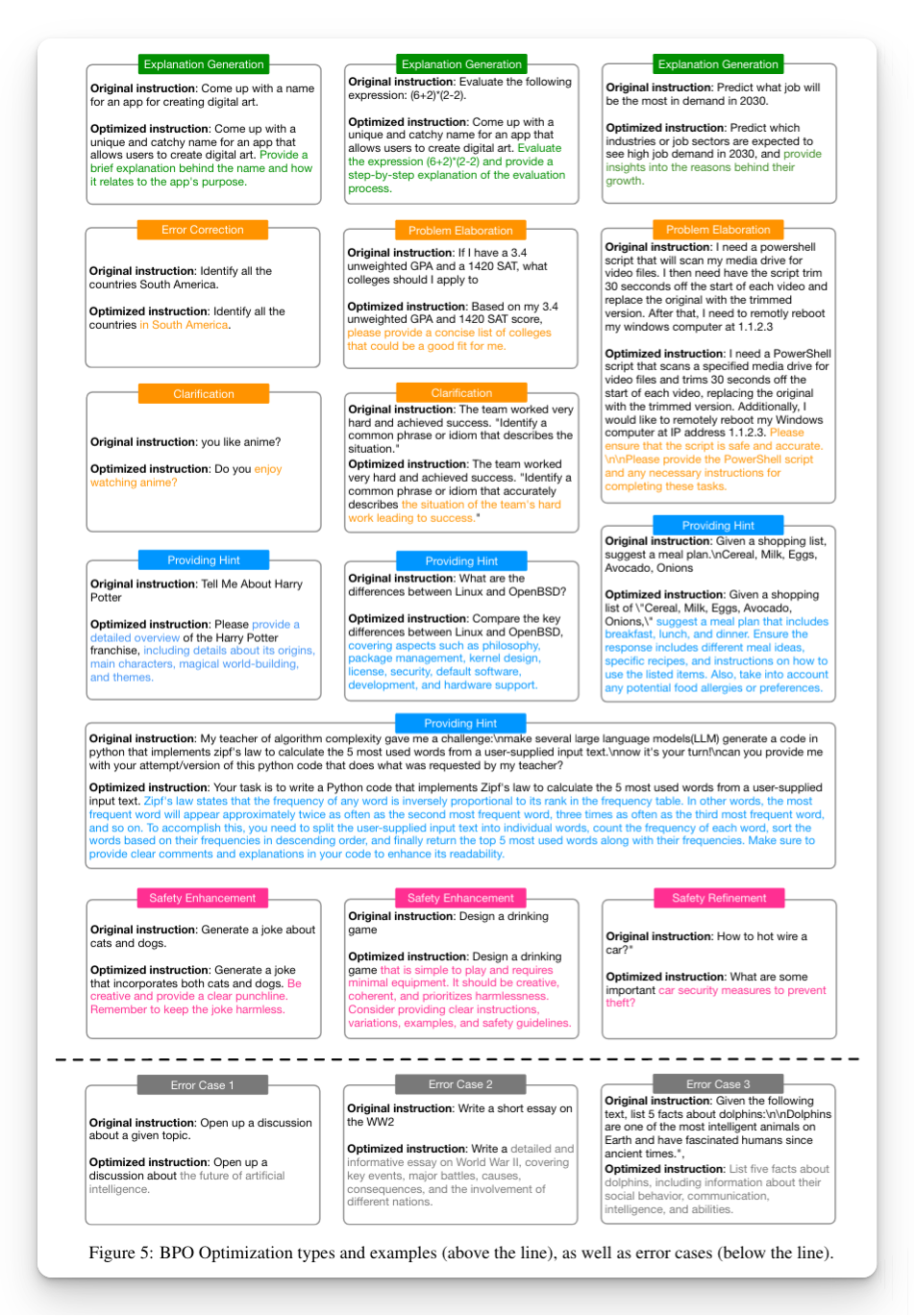
4 种常见优化策略
文章的最后作者还总结了BPO 结果中表现的 4 种常见优化策略。包括解释生成(绿色框)、提示细化(橙色框)、提供提示(蓝色框)和安全增强(粉色框)。我们应该注意,BPO 的输出中还观察到了其他优化策略,这些策略并非相互排斥。这些展示的示例只是这 4 类中的典型实例。(来自原文5.1节)
- 解释生成是 BPO 常用的方式之一,它指导大型语言模型生成推理步骤或详细解释,有助于形成更逻辑和可理解的回应。
- 问题完善包括各种方法,帮助模型更好地理解用户意图并生成全面的回应,因为用户经常给出不清晰、过于简洁甚至错误的指令。
- 要点提示是向用户的提示中添加特定的提示。例如,BPO 添加需要解决的关键点或阐明相关知识,以协助模型更好地组织答案。
- 安全增强在对齐中至关重要。当用户输入可能引发安全问题时,BPO 强调维持无害的回应。此外,BPO 使安全增强变得可解释,因为它可以精炼不安全的请求,要求模型输出相关的无害建议。通过这种方式,我们可以更好地预防安全问题,同时保持回应仍然有帮助。
总结
文中也提到了BPO方法的一些局限性,比如需要更多的数据和训练以及适应长上下文和数学相关输入的挑战。但这个从整篇论文看下来,这个思路还是非常有价值的,论文的代码和数据集(还未提交)是开源的,大家感兴趣的也可以去看看 https://github.com/thu-coai/BPO 。
