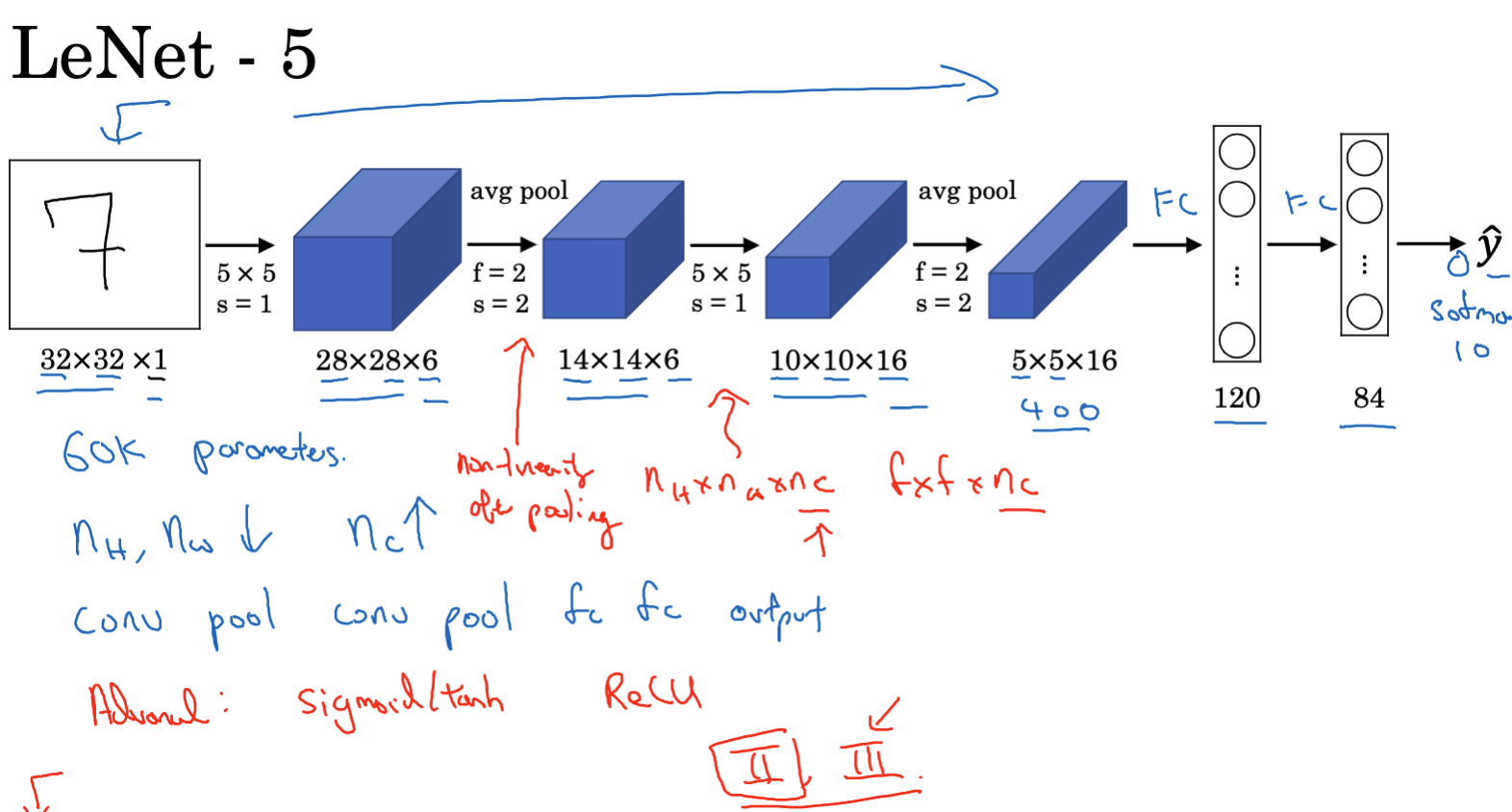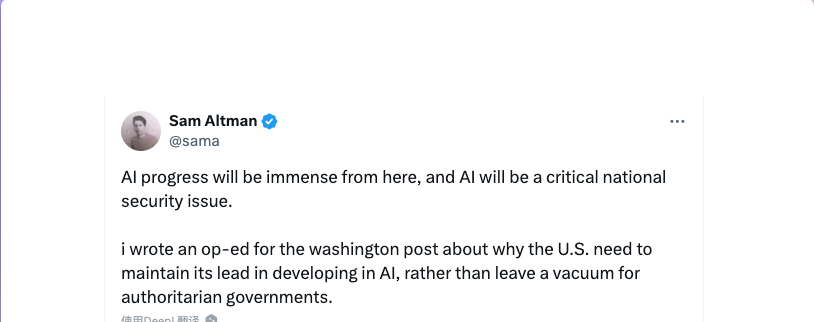
Today, while browsing the social media platform X, I stumbled upon a tweet by Sam Altman from late July. He referred to his article in the Washington Post titled Who will control the future of AI?. Based on his statement, “The U.S. needs to maintain its lead in developing AI,” it is clear that he does not advocate for global cooperation in AI development but rather supports a more authoritarian stance that favors U.S. dominance. I have read various news about him before, and my skepticism about OpenAI’s direction has been growing, especially after the internal turmoil and the departure of the renowned Karpathy. It feels like OpenAI is gradually becoming “CloseAI.” Now, both the closed-source Anthropic and the open-source Meta seem poised to surpass it. Perhaps in the near future, OpenAI will be dethroned.
The main points of his article are as follows:
- American AI companies and industries need to establish strong security measures to ensure our alliance maintains a leading position in current and future models and allows our private sector to innovate.
- Infrastructure determines the fate of AI.
- A coherent AI commercial diplomacy policy must be established, including clear U.S. intentions on implementing export controls and foreign investment rules to build global AI systems.
- Creative thinking is needed to establish new models for developing and deploying AI standards worldwide, with a particular focus on security and ensuring the role of the Global South and other historically marginalized countries.
It is reasonable for Altman to want the U.S. to lead the AI field, just as we would hope for China to achieve industry-leading status. However, this suggests that our domestic developers need to consider not overly relying on foreign models or services and should also focus on domestic manufacturers. Initially, I thought that these domestic large model companies were launching large models for some KPI and would be difficult to use. However, based on the achievements and experiences of various companies over the past year, the gap is not insurmountable.
Since the release of GPT-3.5, the strongest players have been OpenAI and Anthropic. Especially with Anthropic’s recent development trends, they seem poised to surpass OpenAI. I have considered more than once whether to cancel the ChatGPT membership and switch to Claude, but I am currently waiting for the moment it completely overtakes OpenAI. Meanwhile, the domestic large model companies are thriving, and leading enterprises have also open-sourced or partially open-sourced their models. For example, Qwen-2 has topped the Hugging Face LLM Leaderboard. Although the recently released LLaMA 3.1 may be stronger, since it does not support Chinese, the strongest open-source Chinese large model might still be Qwen-2.
The fact that LLaMA does not support Chinese may reflect a mindset similar to Altman’s, emphasizing the U.S. need to maintain its leading position in models. Such a large parameter model, even with Chinese fine-tuning, may not necessarily reach the level of English, making it a less optimal choice for domestic developers or enterprises.
However, domestic developers do have good choices. The domestic large model ecosystem is rapidly developing, and a batch of high-quality models is emerging. For example, besides Qwen-2, there are also Deepseek from Deepthink and ChatGLM from Zhipu, which perform well in specific fields and have a natural advantage in Chinese processing. For developers and enterprises needing Chinese large model tasks, these models are better choices.
As an individual user, I now prefer Deepseek. Without sufficient hardware support, I use its API, and whenever I need a large model API call, my first choice is Deepseek. Moreover, on August 2, they launched the disk cache capability. Half a month ago, I asked their customer service about the token calculation issue for multi-turn conversations because every time a multi-turn conversation required sending all the previous rounds’ content, which resulted in significant token usage. Unexpectedly, they launched the caching capability so quickly. Originally, it was already cheaper than cabbage, and now it is even more cost-effective. (Deepthink, pay up 😄).
Of course, closed-source model products like Kimi from Moon Shadow and Doubao from ByteDance offer good user experiences. The closed-source model I use most often is Kimi, which performs well, especially in reading articles and my self-written Paper-Agent, both using Kimi’s model capabilities.
In this context, domestic developers should pay more attention to localized development opportunities and challenges. Although there is still a gap in AI technology between domestic and foreign countries, this gap is gradually narrowing. By actively participating in open-source communities and promoting technology sharing and cooperation, the domestic AI ecosystem is expected to achieve greater breakthroughs in the coming years. As individual developers or small and medium-sized enterprises, although they may not participate in the foundational large model battlefield, there is still a large market space for model applications.
For commercial use of models, if not using the API of model manufacturers but private training or deployment, small-scale models are difficult to enter the battlefield, and large-scale models are too costly. Will such an awkward situation continue in the future? I don’t think so. As Jia Yangqing recently said, “Is the LLM model size re-walking the path of CNNs?” and as Karpathy mentioned, “LLM model size competition is intensifying… backwards!” The future development of large models may gradually shift towards smaller models, and hardware development, guided by Huang’s Law (though we may not use the strongest version domestically), suggests that resource costs in the large model industry should gradually decrease.
Finally, although the U.S. has a significant first-mover advantage in the AI field, the global AI technology competition landscape is changing. Interactions and games among countries in technological innovation, policy formulation, and market applications will profoundly affect the future development path of AI. For every AI practitioner, how to seize opportunities in this rapidly changing environment and achieve technological and application innovation is a question worth pondering.